- Author:junchen gu (YiboZhu, Chuanxiong Guo)
Distributed Learning
摘要:
Tiresias,一个针对分布式DL训练量身定制的GPU集群管理器,可以有效地调度和放置DL作业以减少其作业完成时间(JCT)。确保DL作业的执行时间通常是不可预测的。
- 我们提出了两种调度算法:
- 离散的二维Gittins指数依赖于部分信息,离散的二维LAS是信息不可知的,旨在最小化平均JCT。
- 此外,我们还描述了何时可以放宽合并的放置约束,并提供放置算法在没有任何用户输入的情况下利用这些观察。
引入:
高效的作业调度和智能GPU分配(即作业布局)是最小化集群范围内平均JCT的关键并最大化资源(GPU)利用率。由于DDL培训的独特限制,我们观察到当前集群管理器设计中的两个主要限制。
- 由于不可预测的训练时间而导致的日程安排。
虽然已知最短作业优先(SJF)和最短剩余时间优先(SRTF)算法可以最小化平均JCT,但它们需要估算一个作业(剩余)执行时间,这对于DL培训工作通常是未知的。 Optimus 可以预测DL训练作业的剩余执行时间。然而,这些建议对于具有平滑损失曲线并且运行完成的工作做出了过度简化的假设;在生产系统中并非总是如此。
正因为如此,生产中最先进的资源管理者相当天真。例如,Microsoft的内部解决方案是从Apache YARN的Capacity Scheduler扩展而来的,该计划最初是为大数据作业而构建的。它只执行
基本的编排,即工作到达时的非抢占式安排。因此,当群集超额预订时,用户经常会遇到长时间的排队延迟
几小时甚至是小工作.
- 在安置期间过度积极的Consolidation.
现有集群管理器还尝试将DDL作业合并到具有足够GPU的最小数量的服务器上。例如,具有16个GPU的作业在每个服务器4个GPU的集群中至少需要四个服务器,如果找不到四个完全空闲的服务器,则可能会阻止该作业。基本假设是应尽可能避免网络,因为它可能成为瓶颈并浪费GPU周期。但是,我们发现这个假设只是部分有效。
本文中,我们提出了Tiresias,一个共享的GPU集群管理器,旨在解决有关DDL作业调度和放置的上述挑战.
- 我们的第一个想法是一个新的调度框架(2DAS),旨在当DL作业的执行时间不可预测时最小化JCT
使这些方法适应DDL调度问题面临两个挑战。
- 首先,在计算其优先级时,必须考虑作业的空间(多少GPU)和时间(多长时间)
- 具体而言,我们的算法中作业的总获得服务共同考虑其空间和时间维度。
- 更重要的是,由于一些工作接受服务,相对优先级不断变化,工作不断被抢占。虽然在启动和停止流程的网络方案中这可能是可以容忍的,但是从其GPU中抢占DDL作业可能是昂贵的,因为必须在主存储器和GPU存储器之间来回复制数据和模型。
为了避免激进的作业抢占,我们在两个经典算法的顶部应用 优先级离散 - 一个作业的优先级在固定的时间间隔后发生变化。
- 我们的第二个想法是尽可能使用模型结构来放松合并的放置约束
总结来说,本文的贡献如下:
- Tiresias是第一个与GPU集群无关的信息管理器。此外,它是第一个将二维扩展和优先级离散应用于DDL作业调度的。它可以有效地安排和放置未修改的DDL作业,而无需任何其他来自用户的信息。如果可以的话,Tiresias也可以利用有关工作的部分知识。
- Tiresias利用简单的,外部可观察的,特定于模型的标准来确定何时放松工作者GPU配置约束。我们的设计实用且易于部署,具有显着的性能改进。
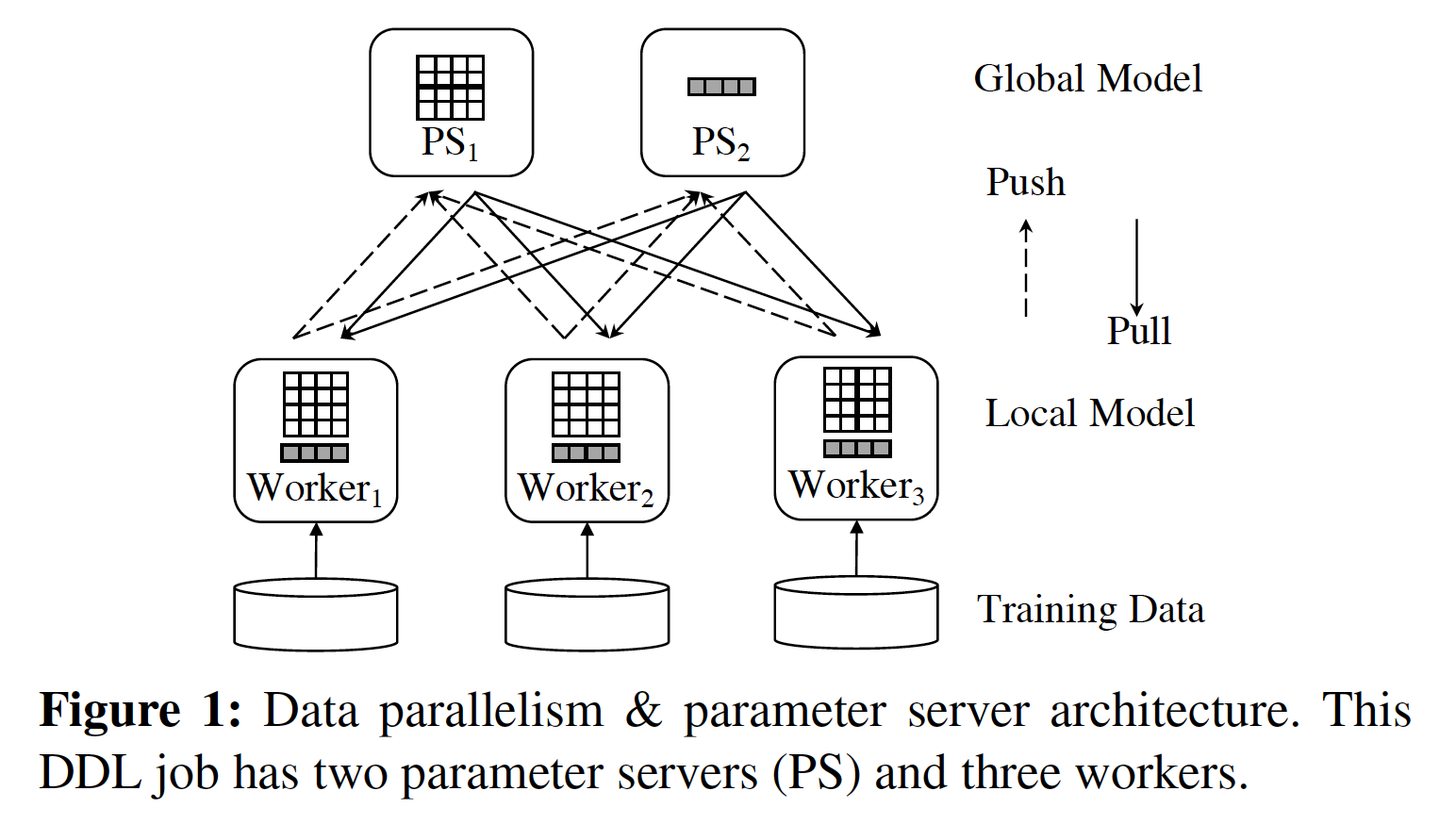
组会随记:
preemption(让路job1换job2)
换出来的时间overlap
三个目标:
1.JCT(job进入队列到集群正式计算,到训完结束)
2.GPU(GPU使用率)
3.No Starvation
challenge:
1.unknow resource 需求
2.unknow job duration
3.unknow dl framework
4.resource allocation (不能不synchronize)
scheduler+placement
需要考虑:job 怎样放在里面GPU-Cluster
Scheuler:
黄色job 1个GPU avg=1.2
红色的job 4个GPU Avg =1 (gpu只有4个,但要等)
所以测量要更多的维度
指标:是已跑的数据和时间乘积
Scheduler的主要设计
优先级离散化->四个不同的优先级
凯的课讲过优先集
consolidation放在同一个gpu里面; 对大的tensor比较好。
Skew level (有贫富差距较大)
2分类问题
优化tensor分布来让网络效率高。
Consolidation
YARN-CS (0-100)
promoteknob(starvation)的判断,避免starvation-time,threshold,starvation