- Author:
Stanford Students PCC, congestion control
第一篇:PCC 较浅队列和公平性
*Authors: Evan Cheshire and Wyatt Daviau
关键result:
pcc探讨了拥塞控制,仍然没有完美的解决方案问题。如此困难的原因是,如文中所见,需要考虑的情景太多。我们对该论文的看法是,作者通过确定广泛解决方案(TCP)所缺乏的地方,假设损失意味着拥塞并改进它来解决问题。
参考:
- [1] J. Jiang, V. Sekar, and H. Zhang. Improving fairness, efficiency, and stability in http-based adaptive video streaming with festive. Proc. CoNEXT, December 2012
- [2] Emulab
- [3] Mininet
- [4] PCC Repository
- [5] Previous CS 244 PCC blog post, Shin and Dia
- [6] ipfw dummynet documentation
引入:
PCC论文的目标是开发一种性能明显优于TCP的传输协议,同时保持一定的实际可部署性。这种性能改进是根据各种网络设置的吞吐量和各种公平度量来衡量的。作者声称,网络事件的hardwired-mapping硬连线映射必然会对关于越来越复杂的网络做出错误的假设。然后,作者提出下一代传输协议应该依赖于更广泛的网络条件实时视图来做出发送速率决策。
PCC通过在执行期间通过以不同速率发送数据来运行A / B测试来实现此目的。该协议将发送方调整到可以最优化效用函数的表现,并以此速率运行。效用函数可以由用户设置,并且通常可以考虑测量的吞吐量,丢失率和延迟。本文测试的实施仅考虑吞吐量和丢失率。引人注目的是,通过这种实用功能,PCC在各种网络条件下的性能提高了近10倍。已经表明,该实现在收敛方面大大超过TCP,并且表现出超出TCP流之间的公平性的PCC间公平性。PCC友好性和实施可能会在虚拟化设置中崩溃,这是以前学生分析的一个主题。PCC建立在UDP之上,因此不需要新的硬件或标头支持。
动机:
我们发现这篇论文很精彩。提高网络性能的问题是计算机网络的核心。为了解决这个问题,作者提供了对TCP使用当前拥塞控制范例的清晰观察,并提出了一种似乎更合理的替代方案。如果作者的评价是公平的,那么这种合理的替代方案一次又一次证明是一种更好的方法来减轻网络拥塞。真正让PCC脱颖而出的是它成功的各种条件,例如卫星,有损或可变链路。satellite, lossy, or variable links
作者的结果:
作者针对许多不同的TCP应变,在许多不同变量的不同环境中测试PCC性能。作者模拟高度丢失的链路和卫星链路,其中PCC优于为各自系统设计的特定TCP变体。
PCC在浅缓冲链路和快速变化的网络上表现得更好,吞吐量高于TCP。除了性能之外,PCC论文在收敛性和公平性方面评估了协议。本文证明了PCC流在竞争资源时比TCP流更好的证据。
我们的子目标和动机:
subset goals
我们决定关注PCC的两个不同方面,其性能特征及其稳定性和公平性。过去的团队在两个敌对网络环境中成功地再现了这些性能提升:卫星和人为有损链接。我们希望我们能够测试不同的网络功能(环境)。浅缓冲实验表明,即使缓冲区保持较小,PCC的部署也可以通过提供流量高吞吐量来缓解缓冲区问题。具体来说,我们的目标是从下面显示的PCC文件中重新生成图7,测量吞吐量与缓冲区大小。
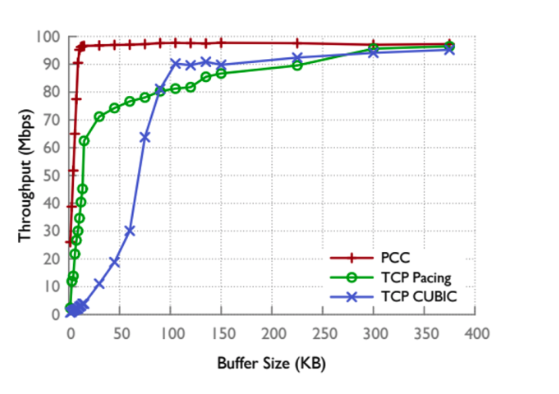
在与Mo Dong交谈之后,我们对多个PCC流之间的收敛性和公平性改善感兴趣 并与TCP相比。这些属性尚未被复制,将PCC应用到视频流对我们很有吸引力,这些应用在发送多个流时依赖于公平性和稳定性。我们决定评估PCC的多流聚合,通过重新创建原始论文的图12来进行评估,以探索PCC是否可以应用到此类特例。
我们的结果:
平台和设置:
我们决定使用Mininet,因为很熟悉,并且它是设置不同拓扑的简单工具。我们在各种AWS-Ec2实例上进行了实验,以便我们可以运行ubuntu机器来支持Mininet和PCC,并保持灵活性,可以尝试更改机器的规格。避免使用本地VM也方便了我们的开发和测试速度。我们不得不从免费的AWS层转移到更大的实例,以便处理系统上的负载,因为较小的实例无法处理4个独立的PCC流的负载并且会崩溃。我们目前的理解是实例类型对结果很重要。特别是对于多流实验,应至少具有8个核心。迄今为止,我们的最佳结果是在c4-2XL实例类型中运行。
此外,我们使用 Emulab网络测试平台在裸机上运行我们的实验,就像最初在PCC论文中所做的那样。这使我们能够更好地理解虚拟化对我们的结果的影响,之前的CS244实验警告说这可能是重要的[5]。 Emulab通过将专用计算机分配为使用ipfw的虚拟网功能连接主机的网桥来模拟网络状况[6]。Emulab emulates network conditions by assigning dedicated machines as bridges that connect hosts with ipfw’s dummynet functionality
我们的两个实验需要单独的拓扑。我们使用简单的两个主机网络运行浅缓冲区队列实验,在Mininet和Emulab的中间有一个开关。一个链路设置为1000 Mb / s,瓶颈设置为100 Mb / s。队列大小范围为5-275个数据包。对于公平拓扑,我们创建了一个wishbone network(叉骨网络),每个发送器和接收器都有一个单独的主机,中间有两个交换机。瓶颈是两个交换机之间的链路,设置速度为100 Mbps。我们选择了一个可以处理带宽延迟乘积的队列大小,以允许TCP实现最大吞吐量,我们计算得到这个队列大小事250个数据包。对于叉骨网络,我们还使用Mininet和Emulab。但是,由于资源有限,我们只能在Emulab上获得两个主机接收的万用网,这限制了我们可以发送的流量。
在这两种环境中,我们使用来自提供的可执行文件——appclient和appserver,以及使用iperf的TCP吞吐量来测量PCC吞吐量。在这两种情况下,吞吐量平均超过60秒,与原始工作一样。我们使用具有本文评估的效用函数的PCC实现。两个实验都使用TCP Cubic与PCC进行比较,因为Cubic包含在我们复制的两个原始数据中,并且是大多数操作系统的默认值。
浅队列结果:
Emulab和Mininet队列扫描的结果如下所示:
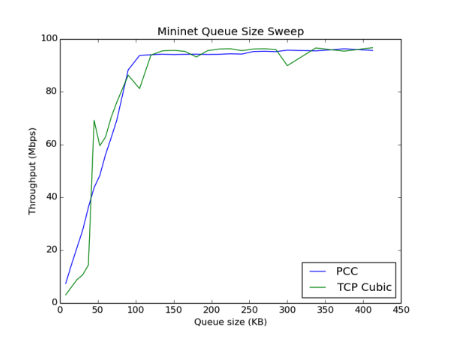
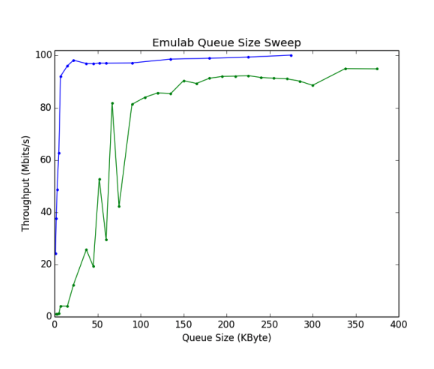
基于Mininet图,PCC在Mininet设置上表现不佳,而不是以原始浅队列图中显示的速率增加。对于Emulab设置而言,PCC符合预期。请注意,TCPCubic的结果在两种环境之间几乎相同。在与Mo Dong谈话并阅读之前的CS244-PCC实验后,我们认为mininet中情况差是因为PCC实施依赖于准确的pacing时间。先前的CS244复现,观察到在虚拟化环境中通过具有浅缓冲器的仿真网络运行PCC时也会有类似的情况很差。目前的假设是PCC依赖于在特定时间发送数据包,但由于Ec2实例的主机操作系统周期性中断,当主机操作系统唤醒时,PCC的均匀节奏会降低为发送更大批量的数据包。必要时,小型缓冲网络在这种突发情况中,丢弃的数据包比在预定时间发送所有数据包要多。这个假设可以解释我们的结果,这表明随着我们增加瓶颈缓冲区大小,PCC性能接近预期值。
注意:我们尝试在专用主机上运行此实验以缓解这些问题,但即使在较大的缓冲区大小,我们实际上也看到了更多的情况不变差。回想起来,这可能是由于我们的专用主机是单核机器,这使得PCC发送器和接收器相互中断并进一步降低节奏。
趋同和公平结果:
以下图像显示了我们在Emulab和Mininet中运行并发PCC和TCP流的结果: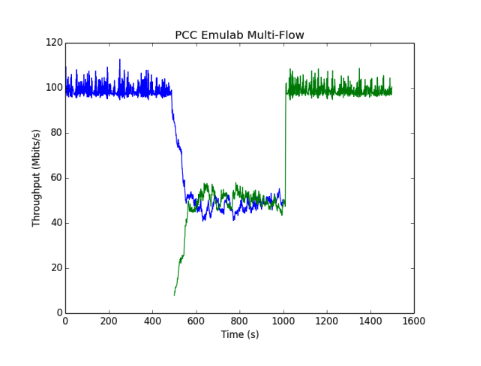
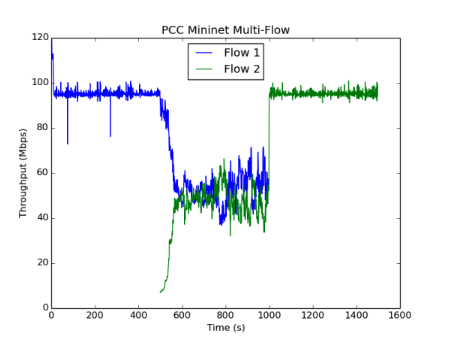
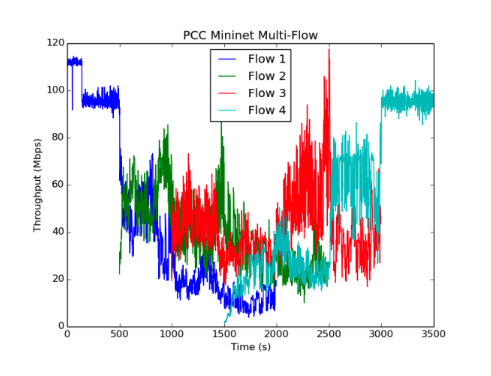
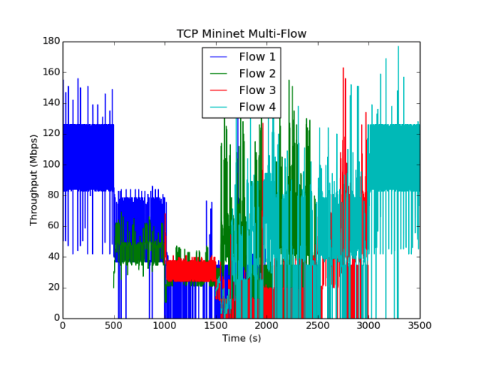
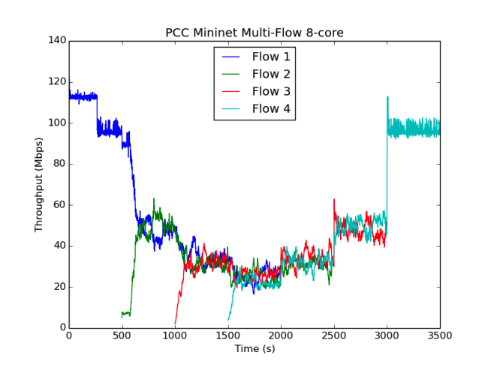
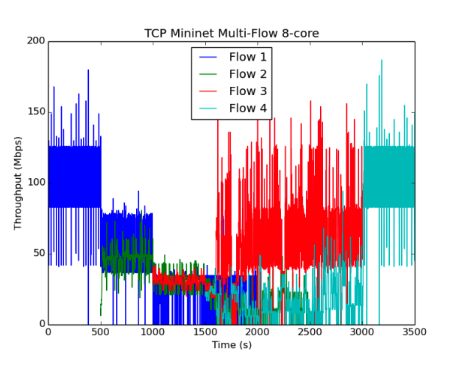
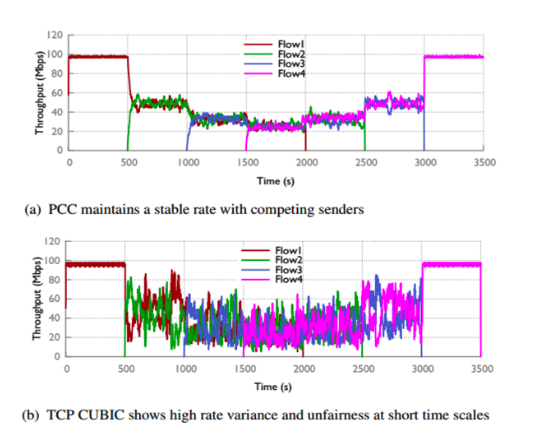
虽然我们的Emulab设置只包括两个发送器和接收器,但我们看到这两个流很快收敛到相同的值并且在运行期间经历了很小的变化,这与原始论文的实验一致。我们运行了几个不同的实例,得到了不同的结果。在m3-large(2 vCPUS),上面显示的“mininet多流”图中,PCC流比TCP流更稳定和更公平,但仍然比原始论文中的图11的流的变化更大。在具有8个虚拟CPU的c4-2XL实例上运行,我们实现了最终结果。即上面看到的“8核mininet多流”图。在这种情况下,不同流量的稳定性和公平性与PCC作者所看到的相当。我们已经包含了一个2流Mininet运行图(在m3-large上),以提供与Emulab数据更好的视觉比较。
(8核的结果最符合原始paper)
为了量化PCC对TCP的改进,我们记录了四流(多流)实验的统计数据。我们测量了平均值Jain的公平性指数,这是一个标准度量,当多个流以100s的时间间隔获得更多的吞吐量时接近1。我们还包括平均标准偏差作为每个流量稳定性的度量,其中较高的吞吐量标准偏差对应于较大的不稳定性。我们对每个间隔的记录的统计数据进行平均化。例如,我们对t=1000-1500s和t=2000-2500s的吞吐量数据进行了3次流量统计。
数据显示,在我们的实验过程中,多个PCC发送者具有更好的稳定性和公平性。在c4-2XL上运行的实验显示与原始论文中报告的结果相当的公平性,其中所有以100s间隔的JFI(jain的公平性指数)在0.98和0.99之间。
挑战:
我们原本以为在t2微秒和纳秒实例上运行我们的模拟就足够了,但是当我们发送3次或更多次流超过30秒时,这些机器会崩溃,因为PCC收敛测试时间较长。
很难在Emulab测试台上花时间在论文的原始环境中运行我们的复制品。由于资源有限,我们只能使用2个发送者和2个接收者,因此无法完全重现收敛性测试。非常感谢Mo帮助我们访问和设置Emulab拓扑。
可能最难克服的挑战是虚拟化对我们的结果的影响的不可预测性。我们目睹了PCC吞吐量的变化,据我们所知,这与不同实例的大小有关。然而,我们的一些观察结果是矛盾的,难以解释。例如,专用主机上的m3-medium显示出比要求的t2-medium更大的浅队列性能下降的问题。从我们的Mininet多流实验设置中获得良好的公平性和收敛性我们遇到了很多麻烦。例如,在m3-medium实例上,流量是公平的,但它们的最大吞吐量是最大值的30%。
批判与结论:
从我们的实验中我们得出了两个主要结论:
- 当在虚拟化环境中运行时,当网络缓冲区非常浅时,PCC实现达到最坏的情况。正是在这些小队列的环境中(由我们的Emulab数据证实)PCC比TCP有很大的优势**,因此这一实例验证结果减少了图7在论文中的影响。**虚拟服务器正在通过互联网超越其裸机配件。部署PCC对于通过这种浅缓冲链路提高这些机器通信的性能几乎没有作用(因为没有大部分都是要在虚拟机上部署,而在虚拟机上部署PCC并不能达到很好的效果)。
公平地说,尽管作者在原始论文中没有提到这一点,但PCC github库在这个问题上提供了丰富的信息。此外,作者声称可以在其实施中修复调步问题。如果能够证明这一点,我们相信它会显著改善评估。
总结: PCC相比TCP CUBIC的优势主要在与shallow buffer阶段,但当buffer shallow的情况是在虚拟机上时,因为pacing的问题,所以这个好处完全被湮灭
- 在虚拟化环境中运行PCC仍然为用户提供了比TCP Cubic更好的收敛性和公平性,只要网络缓冲区足够大并且有足够的处理能力用于发送器和接收器。在少于8个内核的计算机上运行4个流时,我们发现这些属性严重丢失,但在8核实例上运行时,与原始文件的结果相似。我们这一论证得到了PCC Repo的“问题”部分的支持,每个发送者和接收者应该在不同的核心上,以防止损害pacing准确性的性能中断,从而损害公平性和收敛性。我们不知道为什么这些影响会一直扩展到队列大小=250个数据包的时候截止。当虚拟化的不利影响减弱时。作者认为这也是一个实现问题,并且目前正在将SENIC视为一种管理节奏而不是“每个流占用一个核心”的方法。但是,如果有足够的硬件专用于当前的实现,PCC可以提供更好的流量稳定性和公平性比TCP Cubic要好,无论是在虚拟化的环境还是非虚拟机中。
总结: PCC相比TCP CUBIC的优势必须在4核情况下,而且必须是在250个数据包的buffer情况下。
运行我们的实验——使用我们提供的Amazon AMI(推荐)
我们提供了一个Amazon-AMI,您可以使用它来启动我们的代码已经安装并准备运行的EC2实例。要进入设置,请转到AWS EC2管理控制台,然后单击“启动实例”。使用屏幕右上角的区域选项卡确保您的区域设置为“Oregon”。在屏幕左侧的灰色框中,单击“Community AMIs”选项卡。接下来将我们的AMI代码21e21b41复制到“搜索社区AMI”框中。选择此AMI并选择c4-2XL实例类型以启动实例。
要登录实例,请返回到EC2管理控制台并等待实例完成初始化。使用ec2-xx-yy-zzz-aaa.us-west-2.compute.amazonaws.com格式的公共DNS以用户“ubuntu”ssh进入实例。假设您已经在key.pem中跟踪了您的密钥,您的命令将如下所示:ssh -i key.pem ubuntu@ec2-xx-yy-zzz-aaa.us-west-2.compute.amazonaws.com。
获得访问权限后,键入以下命令序列以运行实验并绘制数据。请注意,我们的实验总共运行约3小时(1小时PCC多流,1小时TCP多流,1小时浅队列扫描),所以请耐心等待。我们在两次运行之间都包含了mininet cleanup call,以确保顺利航行。命令:
1 | 已隐藏(需要密钥开启) |
这将进行两个实验,生成TCP和PCC-4流收敛测试和队列扫描。感兴趣的输出图是pccmulti.png,tcpmulti.png和Shallow_Queue.png。这些图将保存在当前目录中,并可以发送回主机以便使用scp查看。此外,多流实验的统计数据应报告给标准输出。
如果您有兴趣重新创建我们的PCC 2-flow测试,请随意修改multi-flow.sh以拥有4个主机,每个主机的flow_time为1000,然后重新运行。然而,该图主要包括与Emulab结果的清晰视觉比较。它是4流收敛测试的子集,因此不需要以重现244为目的。同样,我们具有较少内核的机器上进行了收敛测试,以突出我们的实验过程,但这不是我们提出的核心结果。但是,如果您有兴趣在较少的内核上再现收敛测试图,则只需在m4-large实例中运行AMI并重复上述过程。
莫冬慷慨地帮助我们获得了Emulab,但他无法向所有人伸出同样的礼貌。如果您想要重现结果的Emulab部分,您可以联系Emulab管理员,并可以根据他们的规则申请时间
从头开始
如果您想在没有机器映像的情况下运行这些实验,我们有一个公共git存储库,可用于从头开始设置新实例。启动并登录到新的c4-2XL ubuntu实例并启动以下命令:
1 | 已隐藏(需要密钥开启) |
此时mininet和PCC源与matplotlib一起安装。通过注释掉第303行并取消注释第302行,在文件编辑pcc / sender / app / cc.h中创建具有实用功能的PCC。接下来返回到cs244_researchpcc并运行我们的简单安装脚本来制作pcc:
第二篇:PCC 公平和流量完成时间 Fairness and FCT
引入:
PCC:重新设计拥堵控制以实现一致的高性能。是最近发表的一篇论文,试图设计一种新的TCP拥塞控制方法。作者声称,现有的TCP拥塞控制算法对于TCP必须运行的条件的多样性来说过于严格。根据Dong等人的说法。这种不灵活性源于TCP设计族。每个算法代表信号(例如丢失)和动作之间的“硬连线映射”(例如,将拥塞窗口减半)。 PCC的目标是在各种环境中提供始终如一的高性能,从浅层缓冲网络到卫星链路,到具有许多发送器的数据中心,再到单个接收器。此外,PCC成功地保持了竞争PCC流量之间的公平性。
PCC(面向性能的拥塞控制)试图通过在网络上连续进行测试并尝试通过选择基于这些观察来最大化给定效用函数的动作来修改其行为来实现此目的。此外,PCC确定拥塞只是丢包的可能解释之一,因此不会将丢失用作拥塞的单一指标。相反,效用函数还考虑了吞吐量和延迟。PCC易于部署,因为它不需要硬件支持,并且非常灵活,因为它允许配置效用函数来表达不同的目标。
动机:
我们被这篇论文所吸引,因为它探讨了拥塞控制,这是一个仍然没有完美解决方案的老问题。问题困难的部分原因是,正如文中所见,需要考虑诸多场景。我们对该论文的看法是,作者通过确定广泛解决方案(TCP)所缺乏的地方,假设损失意味着拥塞并改进它来解决问题。
结果:
作者发现PCC在多种情况下在各种指标上优于特殊设计的TCP算法,这证明了PCC的优点和特定情况下TCP的缺陷。如图6,12和13所示,PCC对流量公平性具有更快和更好的收敛性,并且它更好地利用了缓冲区,如图4和图7所示。后者的结果意味着可以构建内存非常有限的路由器。此外,在图15中我们可以看到,在最坏的情况下,这些结果不是以短流程完成时间为代价实现的,因为即使PCC比CUBIC慢,在最坏的情况下它也只减慢20%。
复现目标和动机:
我们对PCC的延迟感兴趣。我们特定选择目标背后有两个主要原因。
首先,这些图不是过去曾参与过PCC的两个团队的主要目标,这意味着我们的结果可以补充他们的全部内容。
其次,我们担心PCC可能过于激进并保持高RTT,尤其是在多个竞争流程中。与Dukkipati和McKeown一致,我们认为流程完成时间是用户体验的重要指标,因此这应该是PCC的主要评估指标。图6和图15(下面描述)的实验设置使我们能够轻松地观察吞吐量 - 延迟权衡。
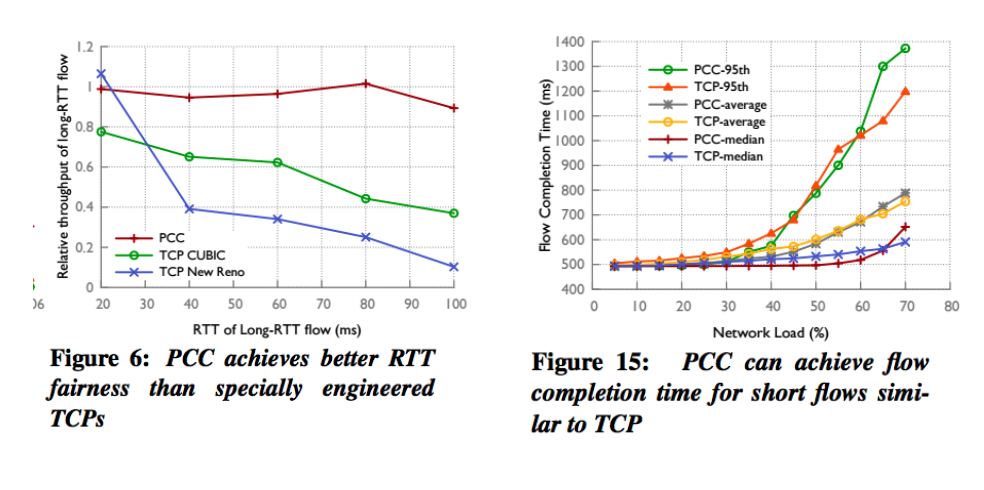
我们的目的是在文献中复现图6和图15。在我们尝试复现论文结果时,我们希望多次运行我们的实验以创建分布并观察吞吐量的跨度。此外,我们希望扩展图15并观察PCC在超过70%的负载下的行为,因为TCP(和PCC)的目标是利用高达100%的瓶颈链路。
##子集结果:
setting:
出于多种原因,我们选择在Mininet上的Google Cloud中重现我们的结果。首先,Google Cloud图像具有高度可配置性,允许在各种计算机上运行实验。此外,gcloud命令行工具可以轻松实现我们在多个图像上的实验自动化和分发。我们对Mininet的特殊选择取决于两个因素。首先,Mininet既熟悉又易于满足我们的特殊需求。其次,原始实验在Emulab中运行,所以我们在Mininet上运行它将显示结果是否依赖于环境。如挑战一节所述,选择一个好的CPU对于复现实验至关重要。
对于RTT公平性实验,我们在Mininet中设置了一个拓扑结构,该拓扑结构包括一个连接三台主机的交换机,作为服务器和两台客户端运行。两个客户端共享到服务器的100Mbps链路,并且在它们到交换机的链路上设置了不同的RTT。短RTT流总是有10ms RTT,而另一流RTT的范围从20ms到100ms。对于PCC实验,我们运行提供的发送器和接收器程序,我们使用它们的吞吐量输出进行测量。对于TCP实验,我们使用iperf作为测量带宽的传统工具。队列大小设置为短RTT流的一个BDP。
对于Flow Completion Time实验,我们在15Mbps,60ms RTT链路上设置了一个简单的Mininet拓扑,其中包含客户端和服务器。我们增加了PCC使它可以报告流程的持续时间,我们再次使用提供的发送器和接收器程序进行实验。为了评估TCP的性能,我们在Go中设置了一个简单的服务器和客户端来报告它们的流完成时间。这个选择是为了创建一个TCP实验,它使用了Dong等人提供的代码中完全独立的代码库。链路的队列大小再次设置为一个BDP。此外,我们将初始TCP拥塞窗口更改为1,如PCC文件中所述。
延迟时间的公平性:
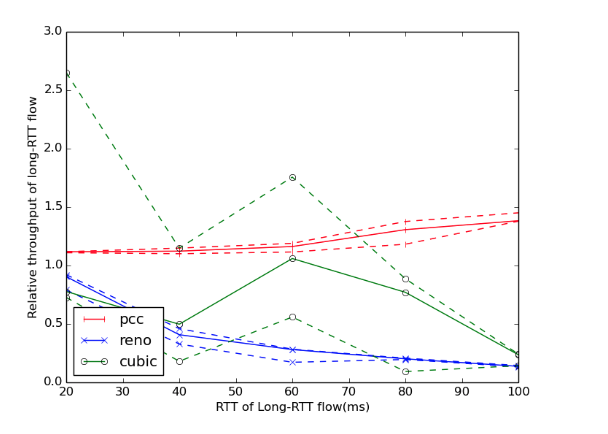
我们进行了三次实验以计算相对吞吐量的间隔,并绘制了最小值,中值和最大值。我们的结果显示TCP Reno和PCC具有非常一致的相对吞吐量,并且这些吞吐量与本文中图6中的吞吐量非常相似。 TCP Cubic产生了广泛的相对吞吐量值,本文的结果是它们的一个子集。由于PCC产生的相对吞吐量始终最接近1,因此验证了该算法在不同RTT流之间的公平性方面优于Cubic和Reno。下图显示了我们实验的结果,包括计算范围。
流完成时间:
我们在流完成时间实验的结果与原始论文中图15中的结果略有不同。作者有PCC和TCP线路开始大约500ms,而我们发现当时很难开始两者,如下图所示。我们认为这是由于我们测量两种协议的流完成时间的方式不同。除了这种差异,我们的结果证实了该论文的总体结果,即PCC不会从根本上损害短流量性能。网络负载的流完成时间在40%以下没有大的变化,对于较重的负载,PCC和TCP显示出与文中的差距相当大。我们运行500个流,从指数分布随机抽取流之间的时间。我们改变指数分布的平均值以实现特定的网络加载时间。对于1到20之间的values值,我们尝试了1/ƛ秒的平均值。我们测量链路级的网络负载,使用bwm-ng测量实验期间的负载。
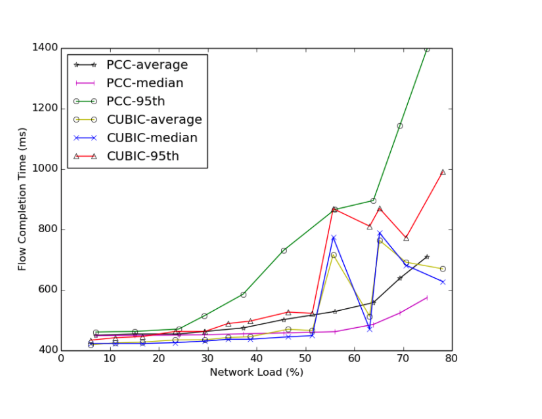
挑战:
我们遇到了与流完成时间实验相关的一些挑战。
测量流完成时间并在TCP和PCC之间一致地执行它是两个不小的问题,因为流开始时具有固有的不同方式。
我们发现PCC由于busy waiting 所以受到CPU的限制,因此大量的流可能会在CPU很少的机器上产生偏差。我们最一致的结果是在具有4个CPU的机器上实现的。
此外,不清楚实验是否以初始TCP拥塞窗口为1运行,但可以从图15报告的RTT统计数据推断出。在固定网络利用率下运行实验很困难,因为指数分布的单个参数化流之间的时间可以产生一系列可能的网络利用率值。出于这个原因,我们使用不同的参数进行了实验,测量了数据点的平均网络利用率,并在这些点上报告了我们的结果。
设置Mininet是一个令人惊讶的挑战,迫使我们重新推荐Mininet的推荐图像,幸运的是运行Ubuntu 14.04,这是该论文作者使用的版本。
总结:
我们试图从PCC论文中复制图6和图15。第一个图描述了PCC关于其他流量的公平性方面,而第二个图描述了PCC流量的流量完成时间。 PCC比TCP更快地实现公平性,同时保持非常相似的流完成时间。我们的实验证实了这两个结果。虽然通过禁用busy waiting使PCC减少CPU密集度是未来工作的一个领域,但该协议产生了有希望的结果,并且对拥塞检测具有重要意义。
复现图15的fct和图6 fairness的图在github的repo中。
我们发现设置虚拟机的最简单方法是设置gcloud工具包。设置完成后,您可以运行以下命令来创建项目和合适的实例:1
2
3
4
5gcloud init ;
gcloud compute images create mininet-image –source-uri=https://storage.googleapis.com/mininet/disk.tar.gz ;
gcloud compute instances create pcc –image=mininet-image –custom-cpu=4 –custom-memory=3840MiB ;
第一行将初始化gcloud工具包并提示您创建项目。
第二行将从我们的disk.tar.gz文件创建mininet图像,
而第三行将从mininet-image创建一个实例。或者,可以使用Web UI从https://storage.googleapis.com/mininet/disk.tar.gz上的URI创建VM映像,然后从映像创建实例。
我们建议至少使用4个CPU和相关的内存数量。
此外,一旦存在实例,请运行以下三个命令:1
2
3
4
5
6wget https://raw.githubusercontent.com/petarpenkov/cs244_pcc/master/run-remotely.sh && chmod +x run-remotely.sh && ./run-remotely.sh
export VM_IP=`gcloud –format=”value(networkInterfaces[0].accessConfigs[0].natIP)” compute instances list -r pcc` ;
ssh mininet@${VM_IP} ;
screen -dr
完成实验后,VM实例的主文件夹中会有一个名为“done”的文件。这是由run-experiment.sh在最后创建的。我们可以为已经设置了所有依赖项和脚本的计算机提供IP地址。出于安全考虑,我们在此处未提供此信息。请联系我们Hristo Stoyanov <stoyanov(at)stanford>或Petar Penkov <ppenkov(at)stanford>。
第三篇: 评估PCC:重新构建具有高性能的拥堵控制
主要结果:
- 在次优网络条件下,具有默认效用函数的PCC确实提供了比TCP更好的吞吐量。
- 但是它对现有的TCP流程非常不友好,
- 并且在共享租赁的虚拟化设置中运行时存在严重问题。我们讨论权衡并在下面提出我们的批评。
资源:
- [1] NSDI ’15: Mo Dong, et. al.: PCC: Re-architecting Congestion Control for High Performance (Version 3) | Website
- [2] Performance Isolation in vEmulab and Mininet vs Mininet-HiFi
- [3] Mo Dong (author)
- [4] PCC unfriendliness discussion with Mo Dong
引入:
PCC论文认为,TCP及其变体本身无法在不断变化的网络条件下始终如一地提供高性能。为了处理复杂的网络行为,TCP依赖于 硬连线映射 - 即针对数据包级事件(如丢弃和RTT增加)的固定响应(如减半cwnd)。在这样做时,TCP隐含地对网络未知的原因和正确响应做出错误的假设。这导致TCP及其变体在实践中产生次优的吞吐量和拥塞控制行为。
使用PCC,客户端运行A/B测试以确定应该发送的速率。它以多种速率发送数据作为实验,并使用观察到的网络行为作为表达所需网络性能特征的效用函数的输入。然后它选择发送的速率以产生最佳输出效用。
可以由发送者设置的效用函数可以选择要优先考虑的性能特征,而不是对网络行为做出假设的协议。因此,作者声称它可以灵活地处理复杂,多变的网络条件。凭借适用于公平性和融合的实用功能,他们认为PCC的性能始终比TCP快10倍,并且不需要硬件支持或新的数据包格式,因此相对容易采用。
动机:
如今,上述条件并非牵强附会。长RTT对应于卫星链路连接和发往全球的数据包,通过多个网络; 高丢包情况一直发生在遭受严重干扰的无线网络和移动网络中。换句话说,PCC声称显着增加吞吐量的条件对应于现代网络中普遍存在的情况。
此外,如果PCC的性能保证是可重现的并且理论上有效,那么它就会引发关于互联网上路由器和客户端应该如何表现的问题。PCC被设计为不需要改变互联网基础设施,但是本文提出的效用函数对现有的 TCP流并不友好,因为它使用与TCP完全不同的拥塞控制模型。PCC客户端很容易饱和并损害TCP流(以及可能是TCP友好的PCC流)的服务质量,因此它引出了一个问题:互联网是否依赖TCP来实现可靠的数据传输。开发最优数据流算法。我们有兴趣探索这一发现的后果。
执行环境:
PCC的作者提供了实现通过UDP传输的PCC协议的源代码。通过一些代码更改,可以更容易地收集有关PCC流性能的数据,我们编译它并在两个设置中运行我们的测试:
Mininet在Ubuntu Amazon AWS VM上(专用c3.4xlarge)。选择它是为了简化和易于再现。
Emulab中的一种真实的物理拓扑,一组可以请求用于研究目的的专用机器。(感谢Mo Dong让我们访问Emulab服务)。我们发现Mininet没有提供最佳性能(如下所述),并选择在Emulab中重现结果以确认paper数据。
拓扑:
与论文一样,我们使用简单的拓扑结构进行测试。两台主机由一台路由器连接。在AWS场景中,此拓扑是通过Mininet的Python API创建的。在Emulab场景中,主机运行Fedora 15,并且桥机运行带有虚拟网络的FreeBSD,以便它可以充当路由器。
我们根据实验改变主机之间链路和路由器的属性(链路延迟,丢包率,缓冲区大小……);
- 在Mininet场景中,这是通过Mininet的Python API完成的;
- 在Emulab环境中,使用ipfw工具设置参数。例如,要将发送方和接收方之间的链路设置为100MB / s,30ms RTT,300KB网络缓冲区和0.3%丢失,我们运行此命令:
1 | ipfw pipe 100 config bw 100Mbit / s延迟30ms队列300KB plr 0.003 |
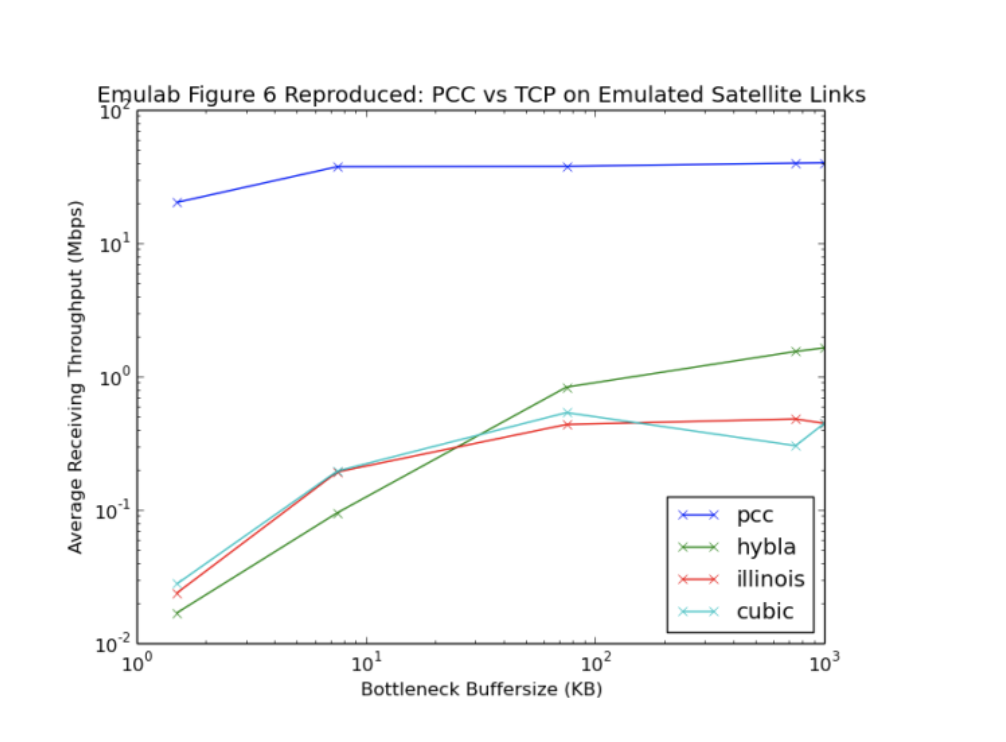
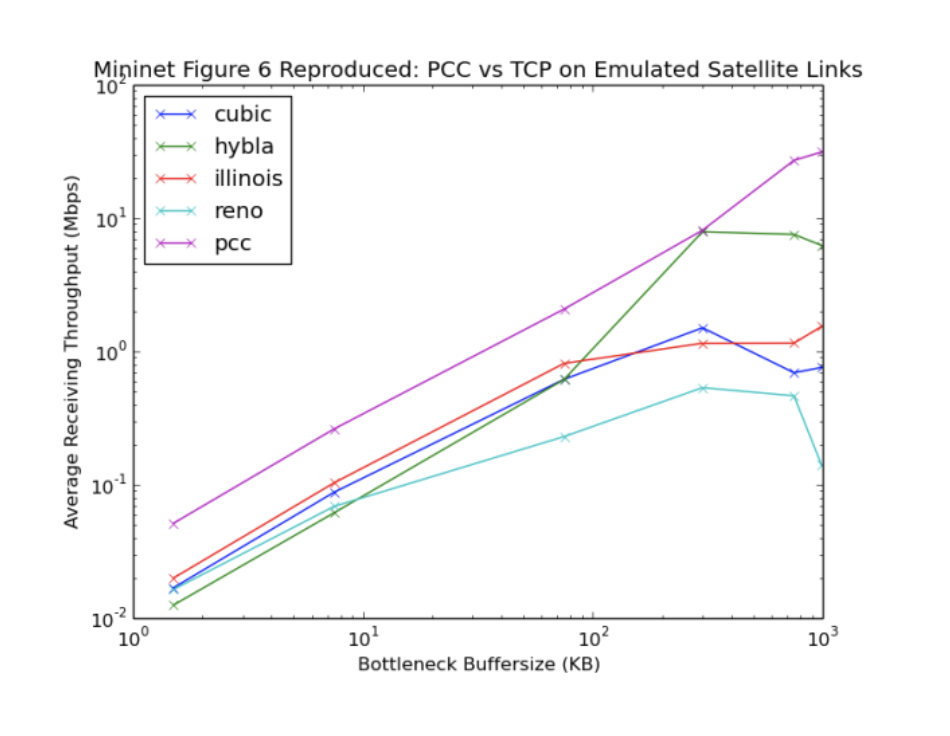
对于图6,我们重现了纸张的带宽拓扑结构,其带宽为42 Mbps,RTT为800 ms,丢失率为1%。我们更改了瓶颈缓冲区以收集我们实验的数据。
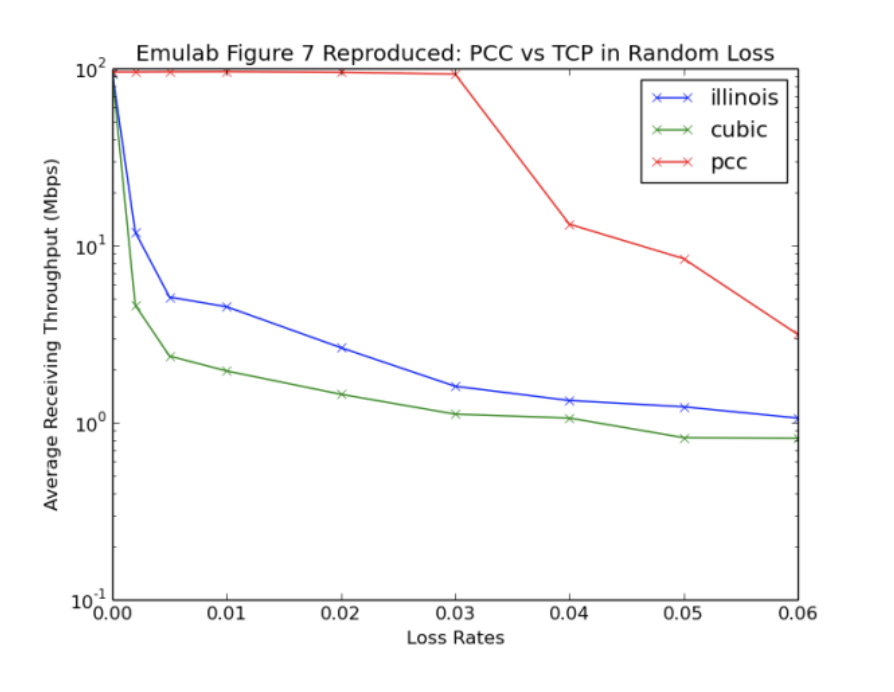
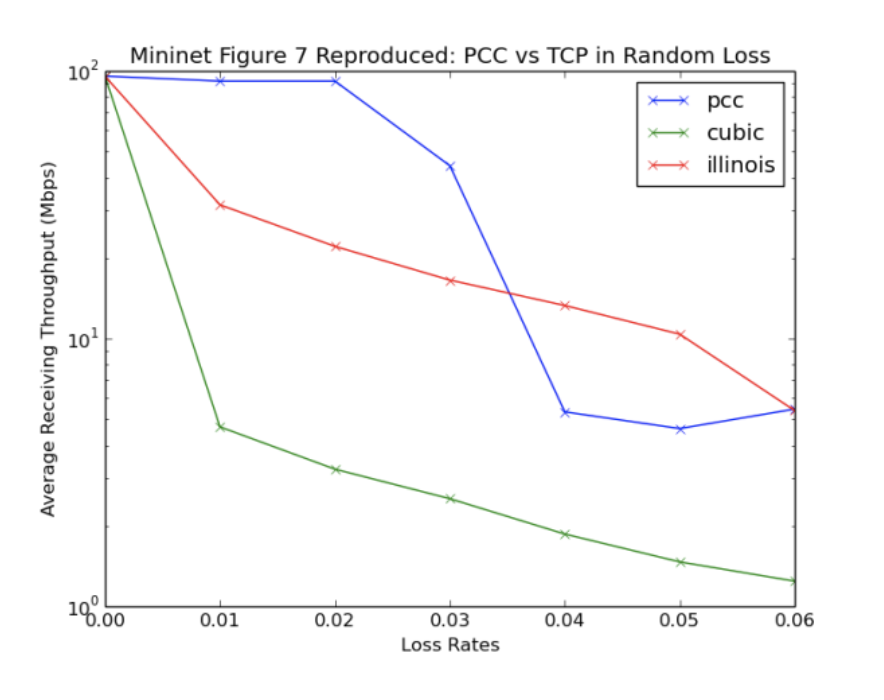
对于图7,我们重现了该文件的带宽拓扑为100Mbps,RTT为30 ms,瓶颈缓冲区为375 KB。我们更改了损失率以收集实验数据。
最后,为了测量TCP友好性,我们建立了带宽为100 Mbps,RTT为30 ms,瓶颈缓冲区为375 KB,丢失率为0的拓扑。
PCC实用功能
对于所有测试,PCC流程使用PCC源代码中的默认效用函数 - 即PCC论文中使用的实验。由于PCC发送者只能观察当地现象,PCC中的所有效用函数最终都会自私。这种特殊的效用函数优化了两件事:低损耗率和高吞吐量。它的设计使其在收敛时还可以在多个PCC主机之间产生公平分配。使用的具体功能在本文的第2.2节中描述。
吞吐量测量技术
我们使用发送和接收数据超过1分钟的TCP和PCC吞吐量的平均值来重现这些数字。我们与莫东谈过,他证实这是实际PCC论文中使用的方法。
图片重现:
图6和图7.图6显示,在具有长RTT的情况下,尽管更改了缓冲区大小,但PCC仍能保持显着更快的吞吐量。使用的TCP变体是Reno(由于缺乏库支持而未在Emulab上生成)Cubic,Illinois和Hybla。正如本文所述,前两个是常见的TCP变体,而后两个分别用于维持损耗和长链路。图7表明,在具有高丢包率的网络中,PCC在TCP受损时保持非常高的吞吐量。使用的TCP变体是Illinois(丢包率优化变体)和Cubic(常见的TCP变体)。我们选择了这些图片,因为它们表明PCC在极端但仍然是现代条件下表现好如果这些图片成立。
TCP Friendness
我们还做了一个我们自己的实验,本文未涉及使用默认效用函数评估 PCC流对TCP流吞吐量的影响。由于PCC的默认效用函数不是为TCP友好性而构建的,我们预计当存在PCC流时TCP吞吐量会急剧下降,这已被证实。
在Emulab的帮助下,我们能够忠实地重现作者的数据并将效用函数归因于提高性能,但在Mininet / AWS环境中,我们观察到了差异。
对于图6,在与Mo Dong直接讨论后,我们认为AWS容器的虚拟化环境可能会降低PCC性能。PCC依赖于随时间推移发送数据包的节点 - 但这依赖于PCC能够在精确的时间发送数据包。然而,虚拟机可能被主机OS中断,导致PCC将发送的数据包延迟并稍后立即发送。对于小型路由器缓冲区大小,我们观察到PCC表现出较差的性能,因为通常会成功的数据包会被丢弃,从而导致PCC频繁地限制其数据包发送速率。这将持续影响PCC收集的统计数据以降低发送速率,从而降低吞吐量。对于较大的缓冲区大小,虽然问题不是那么糟糕,因为缓冲区不太可能被覆盖,与Emulab结果相比,数据包仍可能偶尔以一致的方式虚假丢弃,从而解释次优性能。对于调步问题不严重的缓冲区较大的情形下,我们看到PCC明显优于TCP。
对于图7,有趣的是,Mininet环境中的TCP流量似乎略微好于paper和Emulab结果所声称的,并且PCC似乎比它应该做的更糟糕。虽然上面由于PCC的起搏机制解释了PCC退化,但我们进一步研究了TCP性能的提高,并发现“随着背景负载的增加,TCP流量首先在Mininet中超过了期望的性能”[2]。但是,由于我们在专用AWS实例上运行,因此后台负载没有增加,这解释了TCP的上述最佳性能。这是我们在此过程中发现的一个有趣的副作用。然而,无论如何,丢失率在1-3%之间,PCC明显优于TCP变体。
TCP友好性测试(新颖)
由于5个TCP流以相同的速率运行,我们看到了我们所期望的:通常的TCP振荡,最终越来越接近收敛。当具有默认效用函数的单个PCC流与4个TCP流一起运行时,TCP流经历可怕的吞吐量,并且PCC主导链路。因为它的响应远远少于TCP对数据包丢失的响应, TCP只假设链路本身不能处理尽可能多的流量,而PCC贪婪地占用尽可能多的带宽,解释结果。PCC在这些情况下的行为可以通过考虑TCP的一些反馈机制,通过其中包含TCP友好性的效用函数来改进。


经验教训/挑战
总的来说,我们了解到,在不同情况下复制网络实验和研究网络性能可能会受到实验环境的显着影响。
例如,在我们的实验中,我们尝试采用一种更好地隔离PCC性能的方法是使用likwid-pin将发送器和接收器线程固定到不同的内核,这样它们就不会相互中断。不幸的是,likwid-pin与共享的AWS框没有良好的交互,因此没有缓解上述问题。相反,我们选择了一台高核专用AWS机器来更好地隔离专用内核上的发送器和接收器线程,并在Emulab上重现结果以进行验证。
结论与批判
我们看到将PCC引入真实网络的几个主要问题:
PCC提出的实用功能,正如它现在所设想的那样,对TCP流程不友好,因此很难引入今天的互联网。这很重要,因为大多数互联网都依赖于TCP来发送信息,因此将PCC丢入网络会破坏大量预先存在的流量。
PCC在虚拟化环境中似乎不能很好地工作。鉴于目前许多Web应用程序正在运行虚拟化云服务(如AWS和Azure),PCC实际上可能不适合优化性能,因为它依赖于节奏。我们发现这是最令人关注的结果,因为它没有在论文中直接提及,并且大多数Internet应用程序在今天的虚拟化环境中运行。实际上,该文件直接提到“个体租户可以在其虚拟网络中安全地使用PCC来解决诸如传播之类的问题,并提高数据中心之间的数据传输性能。”
关于第一个,我们意识到虽然PCC对TCP流非常不友好,但有些情况下TCP接受不友好的行为。例如,BitTorrent同时打开许多并行连接,根据Nandita Dukkipati谷歌和许多其他人设置cwnd在打开TCP连接时非常大。因此,有可能PCC可以在不中断其他流量的情况下运行。
关于虚拟化,我们将此问题提交给了Mo Dong。他证实了这个问题,并解释说他的小组目前正在研究缓解PCC pacing问题的解决方案以解决问题,并确认这不是PCC固有的问题,而是当前的实施。如果解决了这个问题,那么PCC在虚拟化设置中也可能有很大的用例。
如果这些问题得到解决,我们相信并且很高兴PCC在压力条件下承诺的性能的显着提升是一个强大的动力,可以被视为TCP的大规模替代品。
重现说明
1 | 已隐藏(需要输入密钥) |