- Author:
Mo Dong(UIUC) congestion control, Reinforcement Learning .
摘要:
由于基本的架构缺陷,TCP几乎没有希望实现高性能。提出PCC(面向结果的拥塞控制),其中每个发送者持续观察其“这一步的操作”与“经验性结果之间”的联系,使其能够始终如一地采用导致更好结果的操作。我们还证明PCC可以达到公平的稳定点。
引入:
TCP拥塞控制性能不佳体现在以下多方面:
- perform poorly on lossy links,
- penalizes high-RTT flows,
- underutilizes high bandwidth-delay product (BDP) connections,
- cannot handle rapidly changing networks,
- can collapse under data center incast,
- incurs very high latency with bufferbloat in the network.
协议补丁在各处盛行,比如高BDP的链路,饱和链路,数据中心,无线网络,以及lossy链路,他们产生更好的效果在某些特定的网络情景下,但是在别的情况下就技不如人。
问题是:怎样获得持续的高效结果,在各种不同的真实网络场景下。
通常大家做hardwired mapping。
特定的packet-level events对应于特定的控制反馈。
- 一个包丢失——TCP New Reno——减半发送率
- 一个包丢失且RTT提升了——Illinois——减小windowsize根据延迟的梯度
丢包层面
hardwired mapping必须对网络做假设,采用教科书事件控制对:数据包丢失使拥塞窗口减半。TCP认为丢包就是拥塞。当这个假设不成立的时候,那TCP就会大大削弱情况。
现代的网络会有巨大的各种各样的情形
- random loss & zero loss
- shallow queue
- bufferbloat
由于手机无线和路径变化,Kbps和Gbbps带宽的不同,AQMs(Active queue mangement),software routers, rate shaping at gateway,virtualization layers and middleboxes like firewalls, packet inspectors and load balancers.这些复杂的网络状况都使得那些教科书式的mapping变得毫无意义。
因此我们提出了PCC(Performanced-oriented Congestion Control)目标是理解速率控制会怎样提升性能高,基于实时经验线索, selective acknowledgement (SACK) delivery, loss, and latency of each packet
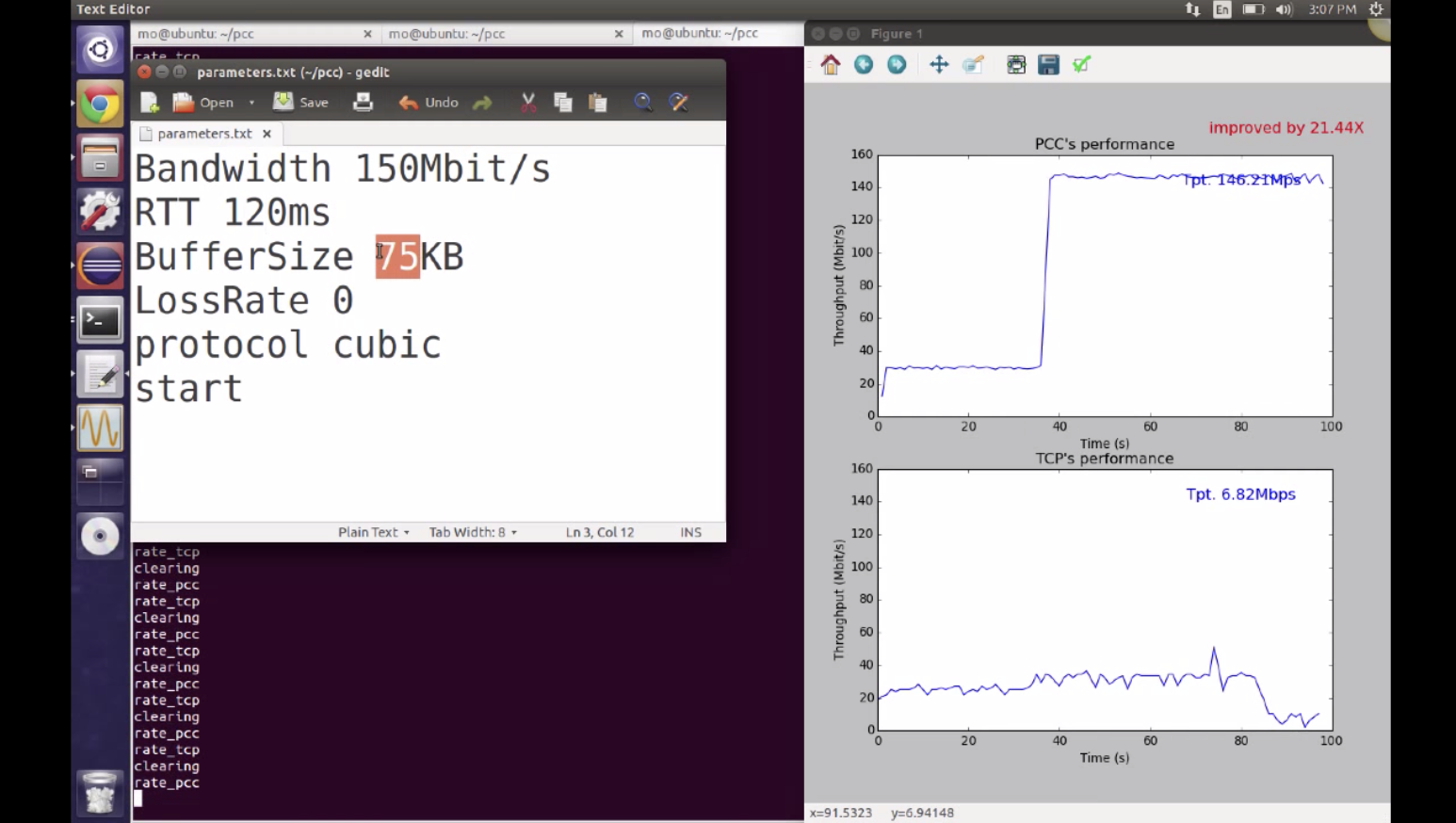
通过这些指标设定了utility function效用函数。PCC使用的是非常通用的效用函数,PCC的收敛时间和TCP相似。PCC获得了较高的统一的表现,并且打败了TCP在以下诸多网络情况中:
- 10倍的TCP CUBIC 在全球化网络情形下
- 5.23倍的TCP Illinois 在数据中心间网络
- 17倍的TCP Hybla 效仿卫星网络
- 10-37倍的Illinois 在不可靠的lossy 链接
- 解决RTT不平均的问题
- shallow缓冲较小的瓶颈链接(性能提升高达45倍)13倍少的缓冲区达到90%的吞吐量
- 14倍CUBIC 5.6倍的Illinois 在不断变化的网络情况下
- PCC和ICTCP表现相同,在数据中心incast网络情形下。
pcc 的网页版
pcc:表现驱动的拥塞控制
TCP的劣势
TCP的表现差是因为TCP简单的hardwiring的包层面的事件->一些预先设定好的控制策略,并不理解真实的动作之后的表现。
TCP假设网络处于某种状态(例如拥塞)并尝试通过触发预定的控制行为(例如,将窗口大小减半)作为对该假定状态的响应来优化性能
但实际上的网络更为复杂:会有以下情况with bandwidth varying by 10,000x, virtualization, AQMs, middleboxes and software routers, shallow queues and bufferbloat, congestion loss and random loss.
所以tcp的假设会失败,但是仍旧会实施不匹配的反应,这就会导致竭股肱的严重下降。
PCC的优势
PCC从TCP失败的地方升起,PCC通过将控制动作(发送速率的变化)直接与其对实际性能的影响相关联。例如,当发送方将其速率更改为r并在以此速率发送后获取SACK时,PCC将这些数据包级事件聚合为有意义的性能指标(吞吐量,丢失率,延迟等),而不是触发任何预定的控制操作。并通过描述“高吞吐量和低损失率”等目标的效用函数将它们组合成数值u。通过这种理解特定发送速率的实际性能结果的能力,PCC直接观察并比较不同发送速率的结果效用,并学习如何通过控制算法调整其速率以改善经验效用。通过避免对潜在的复杂网络的任何假设,PCC跟踪经验上最优的发送速率,从而实现一致的高性能。
高性能开箱即用
互联网上的大数据传输
基于我们在全球商业互联网上的大规模实验,PCC可以在44%的发送-接收对上以10倍击败TCP CUBIC(Linux内核默认值)。我们使用几个代表性样本来比较在使用 PCC,TCP以及用飞机携带100GB传输数据所需的时间。
专用网络上的巨大数据传输
有大量数据(10TB /交付)?拥有一个快速的网络?可以提供专用网络容量吗?不要浪费你的能力!为了测试这种情况,我们在GENI(http://www.geni.net/)Internet2骨干网上配置了多个完全专用的800Mbps链路。以下是在PCC和TCP-Illinois中提供10TB数据的时间。
卫星互联网,在基于真实世界测量的模拟WINDS卫星互联网连接上,PCC提供的数据比TCP Hybla快17倍。
快速变化的网络,我们在网络路径上测试了TCP和PCC,其中可用带宽,丢失率和RTT每5秒都在变化,带宽范围从10Mbps到100Mbps,延迟从10ms到100ms,丢失率从0%到1%。与TCP变体相比,PCC可以紧密跟踪最佳速率。
我们还测试了:
- 不可靠的有损链路(10-37X对比TCP伊利诺伊州)
- 竞争发送方的RTT不均等(RTT不公平的架构解决方案)
- 浅缓冲瓶颈链路(性能提高45倍,缓冲区减少13倍,达到90%吞吐量)
- 数据中心的TCP内容,其中PCC的表现与专用的ICTCP相似。
PCC的控制算法本质上是自私的。令人惊讶的是,它可以实现比TCP更公平和更稳定的收敛。以下是典型的哑铃拓扑收敛实验,100Mbps,30ms延迟瓶颈。四个流以500s间隔顺序到达。每个流发送2000s。
稳定收敛与公平性
PCC稳定地收敛于公平点。
TCP显示非常不稳定的行为。
灵活的表现目标
PCC具有TCP系列范围之外的功能:PCC可以通过简单地插入不同的实用功能直接表达不同的数据传送目标。考虑一种想要获得高吞吐量和低延迟的交互式应用程序,即以优化吞吐量或者等待时间为目标,在先前文献中定义为“power”。
当使用TCP传递数据时,这个交互式应用程序的用户将对落后的用户非常不满经验,因为TCP不知道低延迟目标,仍然积极地填充网络缓冲区并导致恼人的延迟,称为 bufferbloat。为了获得更好的延迟,需要像Codel这样的网内主动队列管理机制或协议栈的fork lift change。使用PCC时,可以简单地将数据传送目标吞吐量延迟作为效用函数插入。然后PCC的控制学习算法将控制发送速率,以凭经验优化该效用函数。