- Author:
YiboZhu(Microsoft, ByteDance) datacenter transport,delay-based congestion control; ECN ; RDMA
摘要:
数据中心网络,尤其是无损RoCEv2网络需要有效的拥塞控制协议。DCQCN(基于ECN)和TIMELY(基于延迟)是两种新型有效策略。在本文中,作者使用流体模型和模拟来分析DCQCN和TIMELY,在稳定性,收敛性,公平性和流完成时间。作者发现了这些协议的一些令人惊讶的行为。例如,
- DCQCN表现出稳定函数非单调
- 而TIMELY可能会收敛到不公平的稳定态
作者在文章中提出简单的修复的方案,来确保两个协议收敛到公平的稳定态。最后,利用从分析中汲取的经验教训,作者解决了更广泛的问题:是否有更本质的理由,证明ECN或者端到端的延迟是一种更好的数据中心拥塞控制信号。基于现代交换机标记数据包的方式,以及由作者推导出的基于端到端延迟的协议的限制,作者认为ECN是一种更好的拥塞信号表征。
关键词:DC,Transport,RDMA,ECN,delay-based,CC
(引入可不要)
引入:
超大的云服务提供商,调整RDMA技术来支持他们最重要的应用。RDMA最重要的是,提供高吞吐量和低延迟,减小CPU的负载量。RDMA使用RoCEv2标准,来确保有效的操作。RoCEv2使用PFC来防止缓存移除的丢包。
近年,有两个很重要的协议,一个是DCQCN,另一个是TIMELY尽管它们都是为数据中心RDMA网络设计的,数据中心基于商用Ethernet硬件,并且没有因为拥塞导致的丢包、它们之间的区别是
- DCQCN使用ECN作为拥塞标志
- TIMELY使用端到端的delay的变化作为拥塞标志
在这篇文章中,作者分析了两者的稳定性,收敛性,公平性和流完成时间。
作者写这份文章有两个动机:
- 第一,要仔细理解DCQCN和TIMELY的表现,对它们是否能广泛部署到潜能做出评估,并对两者给出调参的建议。
- 第二,使用分析中提取出的洞察力,我们想要知道,是否有更本质的理由,来决定选择ECN或者延迟作为数据中心的拥塞控制。
在这个意义下,我们分析了DCQCN,TIMELY,使用流模型(fluid model)以及NS3的模拟。Fluid模型对于分析稳定性,以及参数空间的迅速探索是十分有效的。然而,流模型不能追踪(例如DCQCN和TIMELY)之类复杂模型的所有特征。流模型也不能测量流的完成时间。所以还用细节化的,包级别的NS3的模拟。这一NS3的模拟对比了所有的特征。并且给出了代码
作者说明了两件事:
- ECN或Delay作为拥塞控制,都是基于流的控制。它们均只需商用以太网交换机和NIC硬件的支持,而不需要额外的中央控制器。
2.直接分析DCQCN和TIMELY的结果好坏并没有意义,因为两个协议对于给定的情形,都可以通过调参,使结果变好。作者选择关注更本质的原因。
DCQCN:
- 拓展了fluid model来证明,DCQCN有一个所有流都公平共享流量的固定稳固点。使用离散模型,收敛速度是指数级别的。
- 只要反馈延迟很低,就表明DCQCN在这个固定点附近是稳定的,稳定性与竞争流的数量之间的关系是非单调的,这与TCP的行为非常不同。DCQCN在流的数量偏中等的情况,是不稳定的。
TIMELY:
- 首先设计了一个TIMELY的流模型,且通过模拟证明了它有无数个稳定点,在这些稳定点上,带宽的共享是不公平的。
- 作者提出了一个简单的解决方案,称作为补丁TIMELY,并证明修改过的版本是稳定的,且收敛到唯一的稳定点。
ECN or DELAY:
TIMELY和DCQCN在相同的网络情况下运行,DCQCN在公平性,稳定性,以及对队列长度的控制上都比TIMELY更优异。
从DCQCN和TIMELY分析,作者得出ECN是传递拥塞信息的更好信号:
首先,现代交换机在出口处标记具有ECN的包裹,能做到将队列延迟与反馈延迟解耦,这提高了系统稳定性。
其次,对于使用延迟作为反馈信号的协议,可以实现公平性或保证稳态延迟,但不能同时实现两者,对ECN的协议,可使用类似PI的标记方案来同时实现两者。
最后,ECN信号对反向路径上的震荡更具弹性。因为震荡仅在ECN的反馈信息中引入延迟,而不影响ECN策略下的核心指标。相反的,对于基于延迟的协议,震荡会在反馈信号中引入延迟,从而导致误差。
背景:
RDMA技术提供高带宽,低延迟,较低CPU负载。不再使用主机端内核来进行数据传输,而是采用NIC来将数据传入预先注册的缓存区。
传统数据中心网络,应用RDMA使用RoCEv2标准,RoCEv2需要无损的L2层。以太网使用PFC来达到无损,但PFC会引起HoL队头拥塞问题。这个问题可以通过针对流的拥塞控制来解决。ECN指标或者RTT的增减是两种端到端的拥塞标志。DCQCN,TIMELY分别依赖于ECN和RTT的变化,且这两者都是为数据中心网络设计的。
DCQCN
DCQCN是一个端到端,基于速率控制,使用ECN做指标的拥塞控制协议。它结合了DCTCP和QCN。该算法分为三段:发送端(RP),交换机(CP),接收端(NP)
- CP:在每个出口队列中,如果队列超过阈值,则使用类似RED的算法对包裹进行ECN标记。
- NP:NP接收ECN标记的数据包并使用拥塞通知数据包(CNP)以一定的速率通知RP。
- RP:RP会根据接收到CNP的频率,来调整发送率。RP使用定时器和字节计数器增加其发送速率。
3.1 模型
DCQCN的fluid模型,同时考虑了N个流以相同速率发包,通过同一条瓶颈链路的情形,作者将fluid模型拓展至不同流,不同速率,且作者单独为每个流建模。
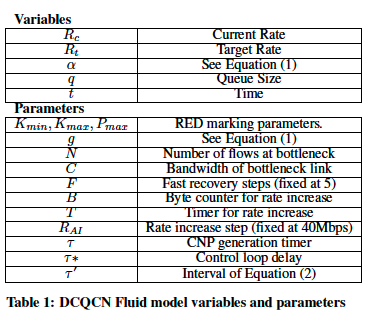
模型验证
作者用NS3模拟了一个简单的拓扑结构——N个发送器同时连接到单个交换机情形。图2显示流模型和NS3模拟器的结果非常一致。
3.2 稳定性
首先作者计算模型的稳定点,并围绕稳定点,线性化模型,使用标准frequency domain技术分析线性化模型的稳定性。
公式 1. DCQCN的固定点
理论证明:DCQCN有唯一的队列长度和流速率确定的稳定点。
由数学公式推知:稳定的队列长度q,由流的个数N决定。以ECN为标志的拥塞控制算法,也可以通过PI-like的机制使得q,与流的个数N无关
稳定性分析
作者根据Bode Stability Criteria 测试系统。稳定度显示为Phase Margin。当固定点存在小的振荡时,稳定的系统必须具有负增益,以便它接受扰动后,回复到固定点。Phase Margin定义为系统距离0dB Gain状态的距离。当Phase Margin大于0时,系统稳定,Phase Margin越大意味着系统越稳定。数值结果如图3所示。

分析了不同条件下的DCQCN稳定性,例如选择不同的控制信号延迟,以及不同个数的流。理想的协议应该能接受控制信号延迟的不同,并且可以扩展到任意数量的流。实际上,由于ECN标记不受拥塞点的队列延迟的影响,因此传播延迟占主导地位。在数据中心环境中,传播延迟通常远低于100秒。可能有数十个流竞争单一瓶颈。如图3所示,具有默认参数的DCQCN在这种环境中下是基本稳定的。
然而,类似TCP,流的个数和Phase-Margin之间的关系不是线性单调的。当延迟很高,对于一定数量的流量,Phase Margin下降到零以后,然后再次上升。对于我们选择的参数集,系统可能在高反馈延迟时具有10个流不稳定。流个数越来越多,DCQCN越来越稳定,这意味着该系统具有良好的可扩展性。在图4所示的流模型结果中进一步说明了这一点。
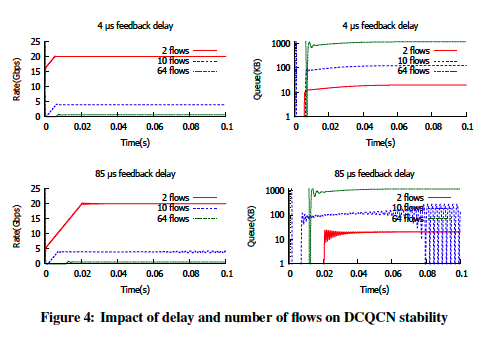
- 当反馈延迟很小(4us)时,不管流的个数如何变化,DCQCN都是稳定的。
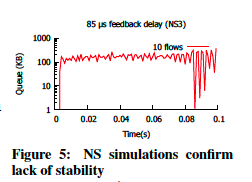
- 当反馈延迟很大(85us)时,DCQCN对于10个流的情况不稳定。但是,对于2个和64个流的情况,它是稳定的。这一结果在图5中显示。
作者发现,这个问题可以通过调整RAI和Kmax的值来轻松修复。
- 较小的RAI意味着流更温和地增加其速率,因而能使系统稳定。
- 类似地,较大的Kmax-Kmin,使得速率降低更缓慢,因为队列长度的扰动导致标记概率的较小扰动。在图3(b)和3(c)中显示了这一结果。
- 因此使用小的RAI和大的Kmax,即使延迟达到100us(这个延迟时间足够大,在现代数据中心网络中也是很稀少),DCQCN也可以始终稳定。
注意到,RAI和Kmax是稳定性和延迟之间的权衡。较小的RAI导致较慢的上升,而较大的Kmax导致较大的队列长度。在大多数情况下,参数在稳定性和延迟之间取得了较好的权衡。
3.3 收敛
在3.2中,作者证明了DCQCN在流量收敛到唯一的固定点后是稳定的。还证明了,在固定点,流量公平分配带宽。然而,有两个问题仍然没有答案:
- 流是否始终收敛到这个固定点?
- 流收敛的速度有多快?
作者在RP处构建速率调整的离散模型。DCQCN速率更新的过程类似于TCP-AIMD 如图6所示。流的峰值速率是Tk。为简单起见,作者假设所有流都是同步的,并且同时达到峰值。这是数据中心的常见假设,尤其适用于分布式存储系统和MapReduce框架的工作负载。
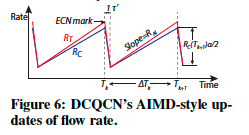
公式 2. DCQCN的收敛性
理论证明:在DCQCN控制下,任何两个流的速率差异随着时间的推移呈指数级别下降
3.4 总结
作者证明了,DCQCN有唯一的固定点,所有流都可以获得瓶颈带宽的公平份额。且流量指数地收敛到该固定点。 DCQCN通常在该固定点附近稳定,如有需要,可以调节RAI和Kmax。但是,基于PI控制器的方法可能是确保稳定性和固定队列长度的更本质的方法。
TIMELY
TIMELY是一种端到端,基于速率的拥塞控制算法,使用RTT的变化作为拥塞信号。依靠NIC硬件来获得细粒度的RTT测量。每次完成16-64KB的段的传输后,计算一次RTT,TIMELY根据这个RTT计算流的新速率,如算法1所示。
如果RTT小于Tlow,则TIMELY会加性递增发送速率。如果RTT大于Thigh,则发送速率乘性递。如果RTT介于Tlow和Thigh之间,则速率变化取决于RTT梯度。如果梯度为正(即RTT增加),则发送速率会与RTT梯度成比例地,乘性递减。如果梯度为负(即RTT减少),则它会以固定值,加性递增。
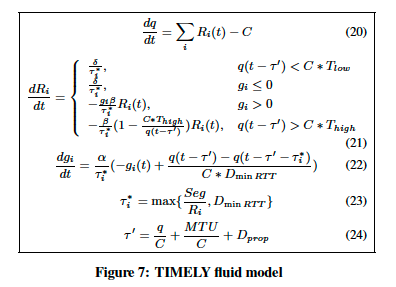
4.1 模型
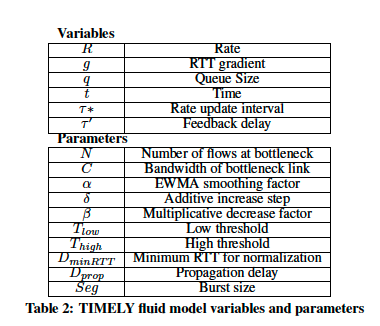
图7和表2显示了TIMELY的流模型:
- 我们对N个流进行建模,这些流都经过单一的瓶颈链路
- 忽略PFC的影响
(流模型(就其本质而言)假定数据的平滑和连续传输。但TIMELY自身的实现机制比较bursty,它是通过调整16或64KB段传输之间的pacing delay来调整发送速率;而段数据本身是以近线率发送的。
TIMELY这么做是为了避免依赖硬件速率限制器。)
模型验证
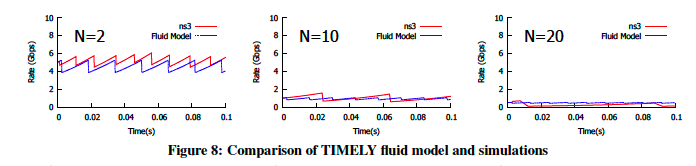
图8将TIMELY流模型与NS3模拟进行了比较,模拟器可以模拟每个数据包的pacing,以及TIMELY的burst行为;这里对包进行pacing。每个流的起始速率设置为链路带宽的1/N。可以看到流模型和模拟器的结果非常一致。
4.2 分析
现在证明TIMELY模型没有固定点,这意味着队列长度永远不会收敛,流的发送速率也不会收敛。该系统会在极限循环中运行,始终振荡。
在系统振荡的同时,流的发送速率存在无限的解决方案。因此,即使可以通过挑选参数,来限制极限周期的大小,但系统仍可在任何稳定点下运行,因此不能宣称TIMELY协议满足了公平性。
公式 3. TIMELY不存在稳定点
理论证明:图7中描述的TIMELY系统,没有稳定点。
公式4. 无限稳定点
理论证明:图7中描述的TIMELY系统,有无限个稳定点。
TIMELY的固定点完全不可预测。如图9的模拟结果所示,其中仅改变两个流的开始时间和初始速率,其他一切保持不变,系统最终会采用完全不同的运作方式。
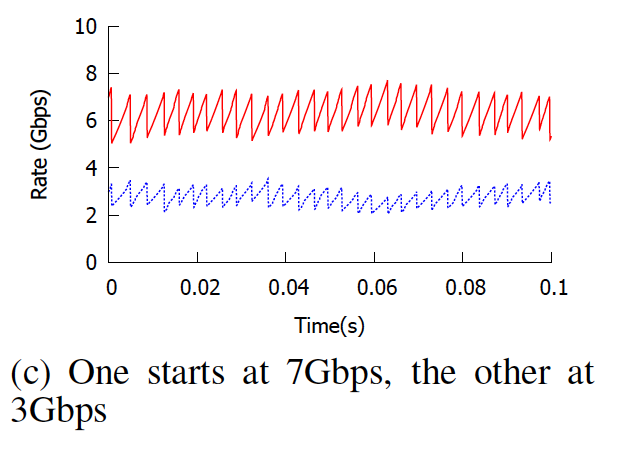
per-burst做pacing的影响
这里的分析是为了说明为什么TIMELY在实践中运作良好?
表面上来看,是因为TIMELY不使用硬件速率限制器。实际上,TIMELY在实际操作中,通过对两个十分大的(64KB)的数据段间的传输间隔做调整,来控制速率。每个数据段,几乎以链路速率或接近链路速率发送。
图9中显示了针对每个burst做pacing的结果。如果用户按每次burst做pacing,则TIMELY则显示出收敛的效果,如图10(a)所示。burst引入了足够的“噪声”以使流之间不相关,这似乎导致系统达到相对稳定的固定点。
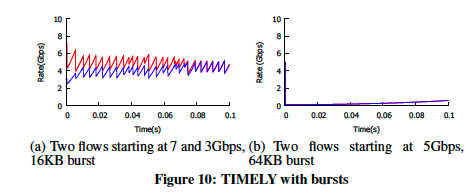
但是在任何情况下,根据burst做pacing的情况都不是最理想的,因为它可能导致队列长度的大振荡,导致利用率低。在图10(b)中显示出来,我们使用64KB的段,两个发送者几乎同时将包发送到交换机,这两个流都接收到非常大的RTT,这会使TIMELY大幅降低其速率,并且随后的速率将以微小幅度增长,流回升到其公平额度,需要很长时间。
通过一些方法可以一定程度上减轻这些问题,例如以低于链路速率的速度发送burst,或调整Tmin阈值。然而,这种调整是脆弱的,因为这些参数的值不仅取决于链路速度,还取决于竞争流的数量,在配置时,这些是未知的。
因此,作者提出了对TIMELY算法的简单修复,而不是依靠burst带来的”噪声”来确保收敛性和稳定性。
4.3 修复版TIMELY
为了确保TIMELY存在唯一的固定点,所有流都得到公平共享的带宽,并且在固定点处达到稳定,作者对TIMELY进行两次小修改,如算法2所示。我们只修改算法1的最后四行。

首先,作者使速率降低的依赖于RTT的绝对值,而不是RTT的梯度。这意味着所有流都知道瓶颈队列长度。这确保了两件事。
- 首先,系统可以具有由RTT确定的唯一固定点。
- 其次,所有流量都可以收敛到相同的速率,因为它们共享瓶颈RTT的值。
- 当然,副作用是,对于不同数量的流,队列的固定点是不同的。我们将在§5中解决这个问题。
其次,作者使用连续加权函数w(g)来使速率增加和速率减小之间的过渡平滑,这可以避免了振荡。这类似于使用概率ECN标记来稳定TCP,DCTCP,QCN和DCQCN的事实。
公式5. 修复版TIMELY具有固定点
理论证明:修复版TIMELY系统具有唯一的固定点,所有流在此固定点具有相同的速率,队列长度可表示。
且系统总是以指数方式收敛到唯一的固定点。
使用模拟进一步验证修补版TIMELY收敛和稳定性。图12(a)和12(b)显示,与图9(c)相反,具有不同初始速率的流会聚到固定点并且在没有振荡的情况下是稳定的。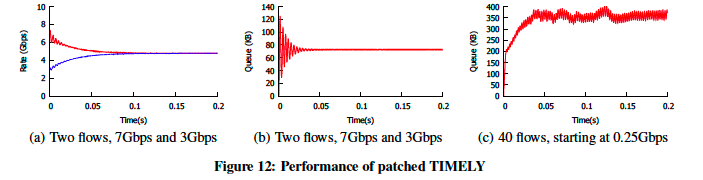
稳定性
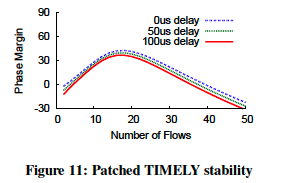
继续对TIMELY进行,拉普拉斯变换,以及计算其特征方程的Phase margin。结果表明该系统在流的个数小于40之前是稳定的(图11)。这再次由NS-3模拟证实(图12)。在流个数超过40之后,Phase margin迅速降至0以下,因为更多的流会导致更大的队列,从而导致更大的反馈延迟,这导致系统不稳定。通常,通过一些微调,TIMELY可以在一定数量的流范围内保持稳定。
4.4 总结
作者证明了TIMELY协议可以有无限的固定点。提出了一个解决方案来解决这个问题,并表明修改后的协议会收敛到一个固定点,其中所有流均等地共享瓶颈带宽。只要流量个数不是太大,系统在这个固定点附近是稳定的。
ECN VS Delay:
如果针对给定场景进行适当调整,DCQCN和TIMELY修改后都可以实现期望的属性,如公平性,稳定性和指数收敛。因此,是否可以得出结论,在拥塞控制方面,ECN和Delay是“等效”的信号?
作者认为答案是否定的。通过比较DCQCN(基于ECN)和TIMELY(基于延迟)的性能,发现DCQCN优于TIMELY。作者解释了基于ECN的协议优于基于延迟的协议的基本原因。
5.1 案例研究:DCQCN与TIMELY的流完成时间
作者表明,经过适当调整,基于ECN的DCQCN和基于delay的TIMELY都可以保持稳定和公平,但可能在其他性能指标上有所不同。例如,用户经常关心流完成时间,特别是对于短流量。作者使用图13中所示的经典哑铃拓扑结构,将DCQCN和TIMELY的流完成时间进行比较。该拓扑由20个节点组成–10个发送器和10个接收器。所有流量都流过两个交换机SW1和SW2之间的瓶颈链路。所有链路均为10Gbps,延迟为1秒。
流由长期流和短期流组成,流大小分布来自报告中的流量分布。可以从指数分布中选取流到达的间隔时间,通过改变分布的平均值来改变瓶颈链路上的负载,这个交通生成模型也用于最近的几项研究,包括pFabric和ProjecToR。DCQCN和TIMELY使用推荐的参数设置。感兴趣的度量是小流的完成时间。在pFabric之后,将小流定义为发送少于100KB的流量。作者还调整、测试不同协议参数和最小流的阈值设置。
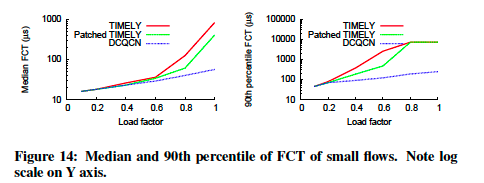
图14显示了当网络负载量变化时,在DCQCN,TIMELY以及修改版TIMELY下,FCT(流完成时间)的中位数和第90百分位数。X轴显示负载,负载因子=1,对应于瓶颈链路上8Gbps流量的平均值。可以看到,在更高的负载下,TIMTY和修补版TIMELY的FCT都很高,且变化很大。这在图15中详细说明,其示出了负载系数为0.8的流完成时间的CDF。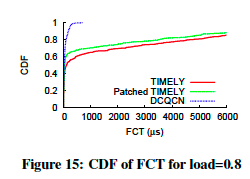
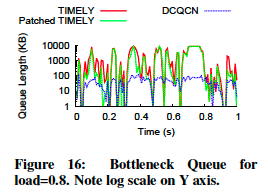
从图16中可以看到,TIMELY性能不佳的原因,图16显示了SW1和SW2之间链路的队列长度,负载系数为0.8。TIMELY框架下,队列长度会增长到非常高的值,并且变化很大。相反,DCQCN队列在RED阈值之间具有固定点,队列长度也始终保持在一定范围内。修补版TIMELY效果介于DCQCN和原版TIMELY之间,是因为修改版确保了唯一的固定点,从而保证了公平性,但不改变TIMELY队列的建立。
注意到,DCQCN和TIMELY的链路利用率大致相同,表明对于长流,两种方案表现基本相似。
5.2 ECN优势
如上图所示,尽管两种协议都是公平和稳定的,但TIMELY比DCQCN的队列更容易震荡,这会影响短流的完成时间。作者认为这是由以下原因造成的:
ECN标记是在数据包出口处完成的,因此具有更快的响应:
现代的共享缓存的交换机,尤其是那些使用Broadcom商用芯片的交换机,在数据包出口处进行ECN标记。当包准备发出时,控制器会检查该端口的出口队列,并标记该包。因此,该标记总是在包离开时传达关于当前队列状态的信息,即使出口队列很长。
而RTT测量是不同的:数据包经历的延迟反映了数据包到达队列时的状态。这意味着由ECN标记仅反应传播延迟,但RTT信号包含了队列延迟,传播延迟两者。这边的区别表明,ECN信号能将传播延迟与队列延迟更好的分离。
(这就是DCQCN流模型,控制回路延迟恒定的原因。DCTCP流模型做出了相同的假设,不能对TIMELY做出相同的假设,因此对TIMELY流模型做出了相应的调整。)
这意味着随着队列长度的增加(当存在更多流时),依赖于RTT的拥塞控制算法在其控制环路中遇到更多的滞后,得基于RTT的控制更不精确。这种情况在TIMELY上发生(如图11)。 DCQCN受这种影响影响较小(图3(a))。为了进一步确认这种分析,作者还设计了如下实验,来证明出口处的ECN标记对于稳定性是重要的,将在入口处运行带有ECN标记的DCQCN和在出口处运行带有ECN标记的DCQCN做比较。图17显示入口处的标记导致队列长度震荡十分严重。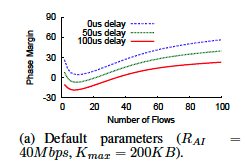
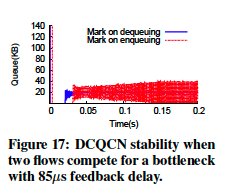
研究人员在解决方案中观察到类似的“缓冲区”的问题,例如LEDBAT。类似地,在现代数据中心网络中,队列延迟往往是导致延迟的最主要的原因。例如,Arista 7050QX32具有40Gbps端口,并且交换机的总共享缓冲区具有12MB。即使在出口端只有1MB的队列,也需要200us才能处理完。相比之下,单跳传播延迟大约为1-2us。典型的直流网络直径为6跳,因此总传播延迟小于25us。
对于基于延迟的控制,固定队列是以公平为代价的:
构建保证延迟固定的一种方法是,使用具有积分控制的控制器,控制器背后的想法是查看差值信号,比如实际队列长度与期望队列长度的差异,并将此差异减小到0。
- 对于DCQCN,可以实现PI控制器来标记交换机处的数据包,并使用该p来实现乘法减少。
- 对于修补版的TIMELY,可以测量终端主机的延迟来实现PI控制器,用这个值作为指标来控制速率。
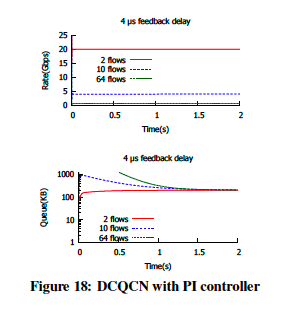
为DCQCN和修补版TIMELY模型使用了PI控制器,并进行了模拟。
对于DCQCN,实验结果如图18所示。所有流都收敛到相同的速率,并且队列长度稳定到预先配置的值。这一点确保了,短流的完成时间不会受到过多队列延迟的影响。
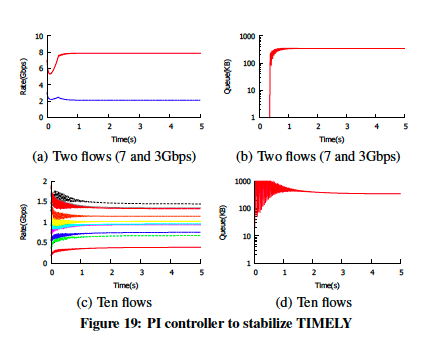
对于修补版TIMELY,添加PI控制器后,可以看到尽管队列长度都被控制在指定值(300 KB),但无法实现公平性(图19)。
接下来,作者证明了一个定理。该定理规范了依赖于端点延迟测量的协议,在公平性和稳态延迟之间的基本权衡,以实现拥塞控制的目的。定理如下:
公式 6. 公平性和延迟的权衡:
对于拥有稳定带宽的拥塞控制机制,吞吐量R是延迟d和差值反馈p的函数,R=f(d,p),如果p基于端到端的延迟测量,那再公平性和固定的延迟之间,两者只能选择一个。
备注:该定理的结果对于使用延迟或ECN作为差值反馈p的拥塞控制协议是通用的。
ECN信号对于变化的反馈传输延迟具有弹性:
最后一点,ECN在回传反馈的时候,对延迟的震动极具弹性。拥塞信号在网络的瓶颈处生成之后,必须被传送回发送方。此过程中的任何抖动或拥塞都可能延迟ECN信号的到达,或影响RTT的测量。尽管DCQCN和TIMELY都试图减轻这种情况。但实际上不能完全消除硬件抖动或反向路径的拥塞。
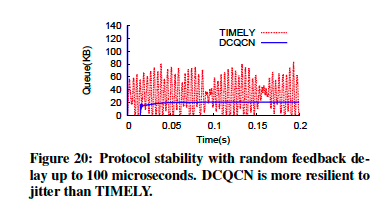
ECN标记对瓶颈处的队列进行长度测量,因此反馈信号不受影响。然而,这一现象会直接在TIMELY反馈信号中注入噪声。这加剧了反向路径上的拥塞或延迟变化问题。模拟证实了这一假设。在图20中,我们将随机抖动注入DCQCN和TIMELY模型的反馈延迟。抖动为[0,100us]时,TIMELY变得不稳定。相反而言,同级别的抖动,不会过于影响DCQCN。
5.3 总结
基于上述三个因素:
- 更快的响应速度,
- 同时实现公平性和延迟不越界
- 对可变的反馈传输延迟的恢复能力
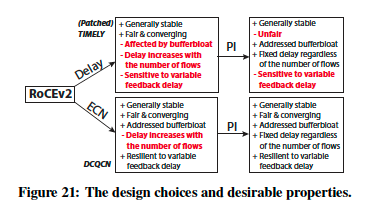
主张使用ECN而不是延迟来实现数据中心的拥塞控制,在图21中说明了这一点。
相关工作:
关于拥塞信号(drop,ECN,delay)拥塞控制算法及其相关的文献很多。下面,作者只讨论代表文章:
现有许多拥塞控制协议,其中瓶颈交换机或中央控制器发挥更积极的作用。例如,RCP和XCP要求交换机发送更详细的反馈,像这样的提议使用中央控制器,进行细粒度调度,而pFabric则是基于超时的拥塞控制,需要交换机对数据包进行排序。
结论与未来工作:
分析了最近提出的两种数据中心网络拥塞控制协议的行为;DCQCN(基于ECN)和TIMELY(基于延迟)
使用流模型和控制理论分析,得到了DCQCN的稳定区域,并且表明了DCQCN的稳定性随着流的个数增加,并不是单调的。
通过数据包级别仿真验证了这种行为。发现DCQCN以指数方式收敛到一个独特的固定点。
在对TIMELY进行类似的分析时,TIMELY协议具有无限的固定点,这可能导致不可预测的行为和不公平。
作者对TIMELY提供了,一个简单的解决方案来解决这个问题。修改后的协议稳定,收敛速度快。
但是,对于这两种协议,队列长度随着竞争流的数量而增加,这会引入显着的延迟。使用交换机上的PI控制器来标记数据包,可以保证DCQCN的有限延迟和公平性。
然而,如果使用延迟作为拥塞控制的唯一反馈信号,那么可以保证公平性或固定的有界延迟,但不能同时保证两者。
基于这个原因,现代共享缓冲交换机上的ECN标记过程有效地排除了反馈环路的队列延迟,并且ECN对反馈中的抖动更加鲁棒,我们得出结论,ECN是数据中心环境中更好的拥塞信号。
未来工作:
对数据中心的RDMA,拥塞控制协议进行全面的PI控制,包括硬件实现。分析还表明,可以通过修改DCQCN,消除单调稳定行为中的异常点。
作者还计划分析由于时间和空间限制,未在文件中涉及的问题。包括多瓶颈情景,更大更现实的拓扑网络,以及PFC导致的PAUSES对这两种协议的影响。为了捕捉这些复杂的行为,需要开发更多的分析工具并提高DCQCN / TIMELY NS3模拟器的性能。