- Author:
Sid Shanker(NYU coder) Congestion Control
0. Several useful tool:
Notebook Tutorial
1.Mahimahi
Network Simulatior
它是一个和NS2;NS3并列的工具,允许开发者在单机测试不同网络情况的工具。
2.indigo
斯坦福SNR(系统网络组)他们正在用RNN做Congestion Control.
indigo is a reinforcement learning-based congestion control algorithM
3.Vagrant
可以使得配置环境变得很容易,轻松起一个虚拟机,配置一个Ubuntu系统
Single workflow to setup a virtual machine
1. Intro to CC:
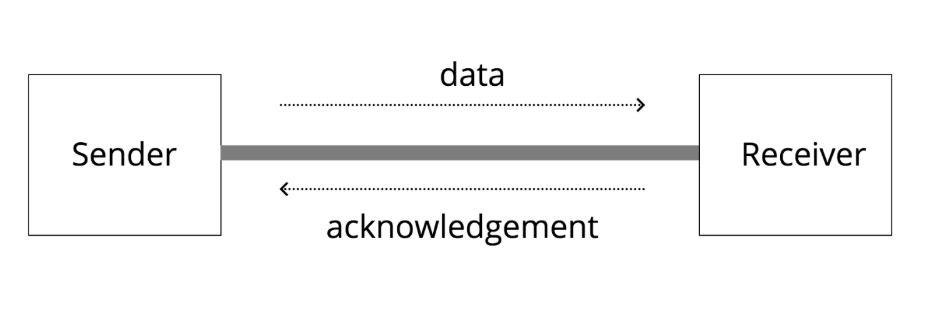
BDP
Link中重要的一个指标是BDP(宽带延迟乘积)是在任何给定时间点可以适合链路的字节数。
这可以被认为是管道中管道的体积类比。
当流经它的字节数等于BDP时,充分利用链路。
如果发送者发送的字节数多于BDP,则链接的队列将填满并最终开始丢弃数据包。
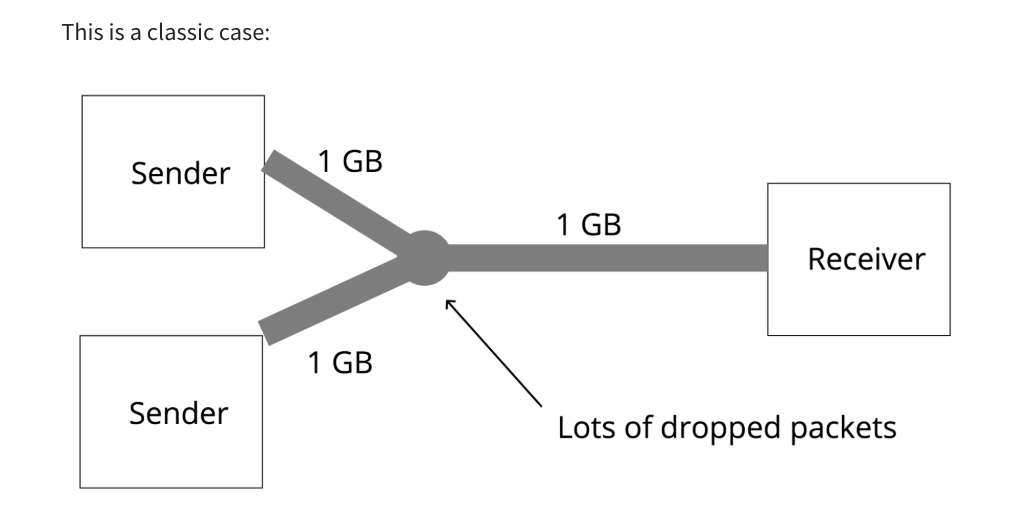
Tahoe
惨遭淘汰的原因是在bandwidth较高的网络中,Tahoe 需要太长的时间才能收敛到高bandwidth。
Cubic
Linux上标配算法,仍用Packet Loss作为拥塞指标
BBR
Google提出,且用delay拥塞作为指标
Fairness
不同算法之间可能会产生公平问题。有些算法是贪心的,可能相比别的算法占据更多的带宽。
2. CC Cubic:
Cubic VS Tahoe
现在大多数网络都是long,fat networks。需要更快达到一个更大的cwnd。
Cubic(三次函数)使得更快得收敛到更好的网络状况.].
CUBIC和另一种机制一起Send的时候会表现更好。看似奇怪,实际上是因为当有Multiple Sender的时候,link Queue 会更快的填满queue,导致packets 开始丢包。较早的更正阻止CUBIC进入窗口增长非常快的状态。除此之外,Tahoe比Cubic遇到拥塞时减少得更快,这意味着当丢失事件发生时,CUBIC有更多的队列空间可供使用。
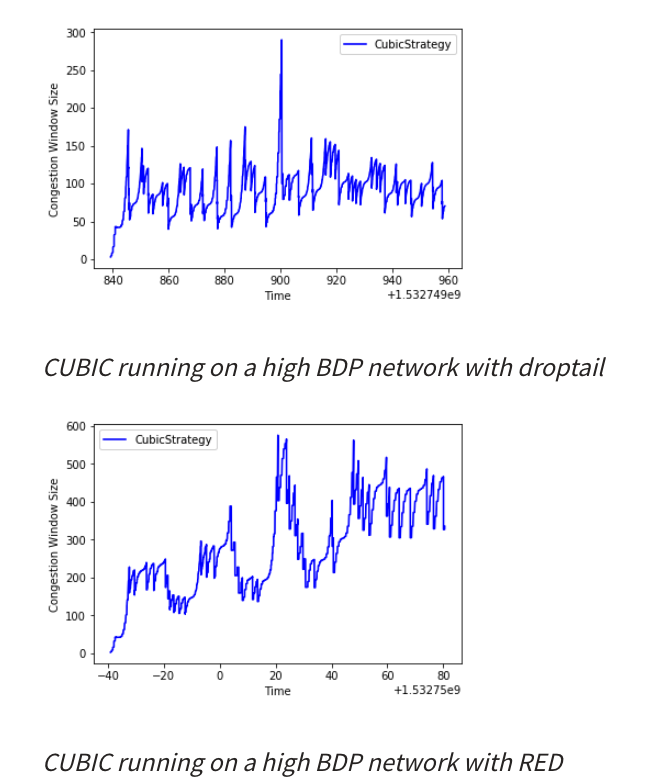
缺点:高BDP时,大的Queue队列可能导致Cubic表现差。由于Cubic在发生数据包丢失之前不会减少窗口大小,因此较大的队列可能会掩盖发送方窗口太大的事实,其实已经拥塞出现,但Cubic不知道还在增加窗口,不断增长的队列会导致往返时间增加。
3. CC Red:
Red CC Algorithm
Red是一个router端的拥塞控制算法。
【1】为什么仅用丢包来处理CC会有问题?
如Queue大,我仅用丢包作为拥塞指标。实际已经拥塞的情况,但是还没出现丢包,CWND仍旧在增加,未减少,如Cubic。它很难充分发挥其潜力,因为它太晚才得知拥堵发生。
它有点像淋浴中的热水旋钮,在您移动旋钮后发生反馈,而您直到后来才意识到它是否过热。
【2】为什么不能减少队列?
队列可以作为平滑功能,可以吸收突发的流量并在链接被清空时保留它们。
使队列变小使得它们对交通爆发的抵抗力降低。
【3】我们怎么做?
采用
AQM(主动队列管理)算法处理此问题的传统直观方法称为droptail。队列不必等到它们全满就开始丢弃数据包。
引入
RED(Random Early Detection)随机早期检测(RED)是一种排队规则,可以按概率从队列中丢弃数据包,其中该概率与队列的满载程度成正比。队列越满,丢弃的概率就越高。
丢掉一个完好的包虽然有点违反直觉,但任意丢弃完全健康的数据包会带来更好的性能。直觉是,早先丢弃数据包为TCP发送者提供了一个指示,即他们应该减少拥塞窗口。这比完全填满队列,体验一系列丢弃,然后不得不Cut拥塞窗口要好很多。
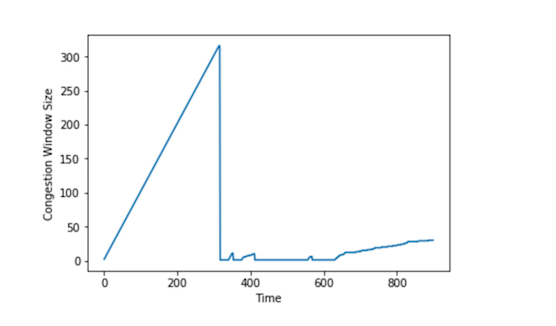
【4】RED 算法的 Bug
值得注意的是,在一些实验中,拥塞窗口将崩溃为零,而且永远不会恢复。我们会在拥塞窗口中看到这样的图形:
4. CC Reinforcement Learning :
State使用per packet RTT 的历史作为state.Actionincrease the cwnd // decrease the cwnd // keep sameRewardfunction sender increases the window and that 同时也增加了 RTT => negative reward . 如果没有增加RTT => Positive reward.Train
我们的state是连续的历史性的,所以用了LSTM。我们跑了一系列的episode,每个episode跑一分钟,每次ack已收到,就选择一个action,并且追踪RTT给agent一个相应的reward。Transitionthe current state
action
the resulting state
reward
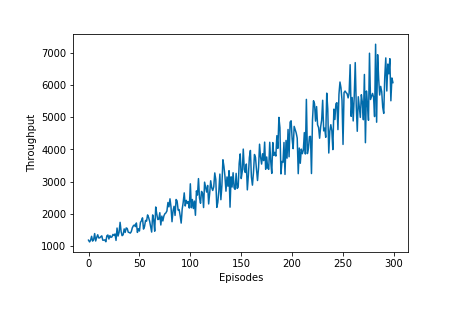
随着更新迭代,结果一直在提升,变得更好。
Future work在我们的实验中,这个结果没有收敛,所以我们需要更长时间去跑到收敛。
同时我们也参考了Pantheon Pantheon