- Author:
Liang Luo(University of Washington Microsoft Research) Distributed Machine Learning, Parameter Server
What This paper talking about:
Distributed DNN Training is Communication Bound
Distributed Cloud DNN training time is chiefly spend waiting for parameter exchanges.
Compute engines shift training performance bottleneck from computation to communication.
(1) Insufficient Bandwidth (2) Framework Bottlenecks (3) Deployment-related Overhead These are three bottleneck in cloud-based DDNN training
PHUB :Optimized Parameter Server
On MXNet, our profiling of MXNet reveals two problems:
(1) insufficient network bandwidth
(2) an in efficient PS software stack
Network Stack
optimized InfiniBand Support for lower network overhead, with one-shot registration, zero copy and minimized metadata. So all bandwidth is dedicated to gradient payload.
Aggregation and Optimization
Fine grained key chunking for maximized overlap of network transfer and gradient processing.Optimal load balancing in processor cores; locality-preserving, vectorized implementation of aggregator and optimizer.
Gradient Memory layout
NUMA aware, balanced scheme for assigning a key chunk to a processor core, through a series of load-balanced, locality-preserving assignment of queue pairs, interfaces ,completion queues to cores. PHub incurs zero synchronization between cores or between NUMA domains.
software alone is not sufficient
Single interface/connection in the server must handle traffic for all participating workers. Propose PBox, a new server architecture that balances IO, memory and network bandwidth.
Contribution:
A detailed bottleneck analysis of current state-of-the-art cloud-based DDNN training
Design and implementation of the PHub PS Software
A balanced central PS hardware architecture, PBox to leverage PHub for rack-level and hierarchical crosss-rack gradient reduction
A comperhensive evaluation of PHub in terms of performance, scalability, and deployment cost
What i learned:
Cloud-Based Training:
forward pass
backward pass
backpropogation
updated
GPU thousands of samples
Key value stores:
PS are specialized key value stores that collect the gradients and update the model. key refer to layer and value refer to the set of parameter for that layer
Common PS configuration has 4 kinds:
Colocated Centralized (CC)
Non-colocated Centralized (NC)
Non-colocated Shared (NCS)
Colocated Shared(CS)
MXNet Framework:
MXNet is a widely used on AWS
And its PS implementation relies on TCP ,built on top of the ZMQ distribted messaging library.
ØMQ是一个为可伸缩的分布式或并发应用程序设计的高性能异步消息库.
GPU CUDA CuDNN 的理解:
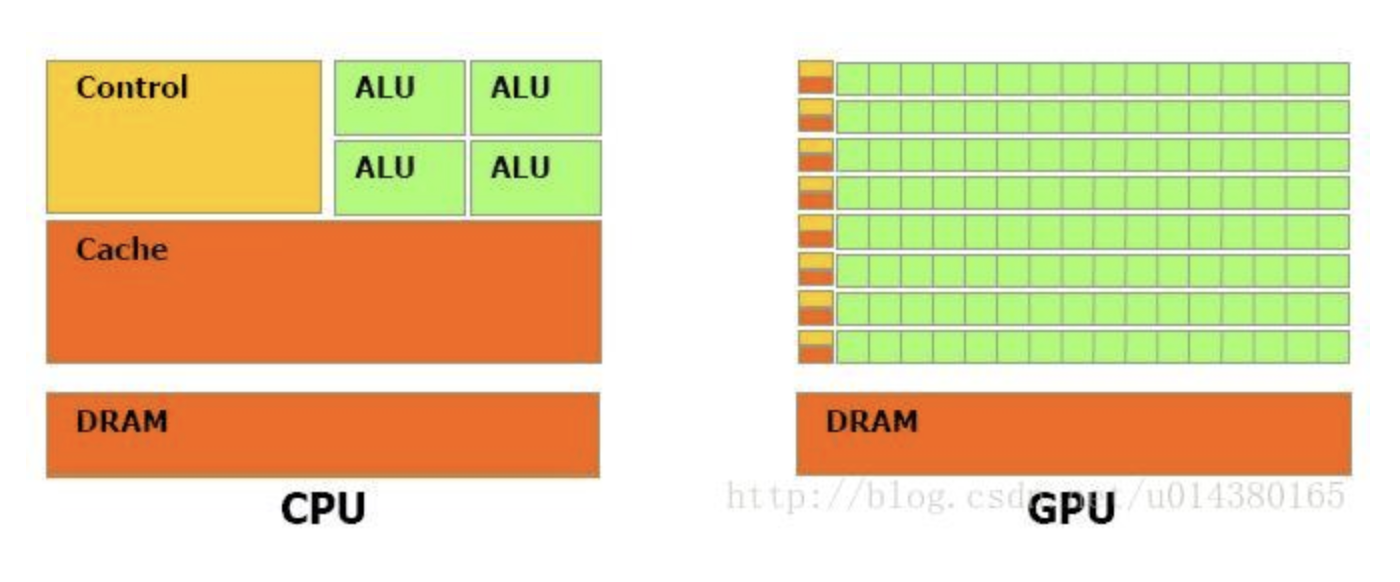
GPU VS CPU
GPU 相比 CPU 有更多的运算单元 ALU , 而 Control 和 Cache 的单元不是很多,这是因为GPU在进行并行计算的时候每个运算单元都是执行相同的程序,而不需要太多的控制。
Cache 单元是用来做数据缓存的,CPU可以通过Cache来减少存取内存的次数,GPU中Cache很小,因为可以通过并行运算减少内存延迟
因此CPU的Cahce设计主要是实现低延迟,Control主要是通用性,复杂的逻辑控制单元可以保证CPU高效分发任务和指令。所以CPU擅长逻辑控制,是串行计算,而GPU擅长高强度计算,是并行计算。
打个比方,GPU就像成千上万的苦力,每个人干的都是类似的苦力活,相互之间没有依赖,都是独立的,简单的人多力量大;CPU就像包工头,虽然也能干苦力的活,但是人少,所以一般负责任务分配,人员调度等工作。
可以看出GPU加速是通过大量线程并行实现的,因此对于不能高度并行化的工作而言,GPU就没什么效果了。而CPU则是串行操作,需要很强的通用性,主要起到统管和分配任务的作用。
CUDA
CUDA的官方文档(参考资料1)是这么介绍CUDA的:a general purpose parallel computing platform and programming model that leverages the parallel compute engine in NVIDIA GPUs to solve many complex computational problems in a more efficient way than on a CPU.
换句话说CUDA是 NVIDIA推出的用于自家GPU的并行计算框架,也就是说CUDA只能在NVIDIA的GPU上运行,而且只有当要解决的计算问题是可以大量并行计算的时候才能发挥CUDA的作用。
在 CUDA 架构下,显示芯片执行时的最小单位是thread。数个 thread 可以组成一个 block
一个 block 中的 thread 能存取同一块共享的内存,而且可以快速进行同步的动作。每一个 block 所能包含的 thread 数目是有限的。不过,执行相同程序的 block,可以组成grid。不同 block 中的 thread无法存取同一个共享的内存,因此无法直接互通或进行同步。因此,不同block中的thread能合作的程度是比较低的。
不过利用这个模式,可以让程序不用担心显示芯片实际上能同时执行的thread数目限制。
例如,一个具有很少量执行单元的显示芯片,可能会把各个block中的thread顺序执行,而非同时执行。不同的grid则可以执行不同的程序(即kernel).
CuDDNCuDDN是NVIDIA打造的针对深度神经网络的加速库,是一个用于深层神经网络的GPU加速库。如果你要用GPU训练模型,cuDNN不是必须的,但是一般会采用这个加速库。
The NVIDIA CUDA® Deep Neural Network library (cuDNN) is a GPU-accelerated library of primitives for deep neural networks.
CuDNN provides highly tuned implementations for standard routines such as forward and backward convolution, pooling, normalization, and activation layers.
cuDNN is part of the NVIDIA Deep Learning SDK.
SDK=软件开发包
Some of GPU NAME:
- Grid K520
- K80
- M60
- GTX 1080 Ti
- V100
- TensorCore V100
Amazon EC2g2, p2, g3 and p3
Amazon EC2 为您提供了一个真正的虚拟计算环境,让您使用 Web 服务接口启动多种操作系统的实例,通过自定义应用环境加载这些实例,管理您的网络访问权限,并根据自己需要的系统数量来运行您的映像。G2 instances are designed for applications that require 3D graphics capabilities. The instance is backed by a high-performance NVIDIA GPU, making it ideally suited for video creation services, 3D visualizations, streaming graphics-intensive applications, and other server-side workloads requiring massive parallel processing power.
With this new instance type, customers can build high-performance DirectX, OpenGL, CUDA, and OpenCL applications and services without making expensive up-front capital investments.
zero-copy
零复制(英语:Zero-copy;也译零拷贝)技术是指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域。
这种技术通常用于通过网络传输文件时节省CPU周期和内存带宽
你可以用一种叫做Zero-Copy的技术来去掉这些4次user模式和kernel模式的copy。
应用程序用Zero-Copy来请求kernel直接把disk的data传输给socket,而不是通过应用程序传输。Zero-Copy大大提高了应用程序的性能,并且减少了kernel和user模式上下文的切换
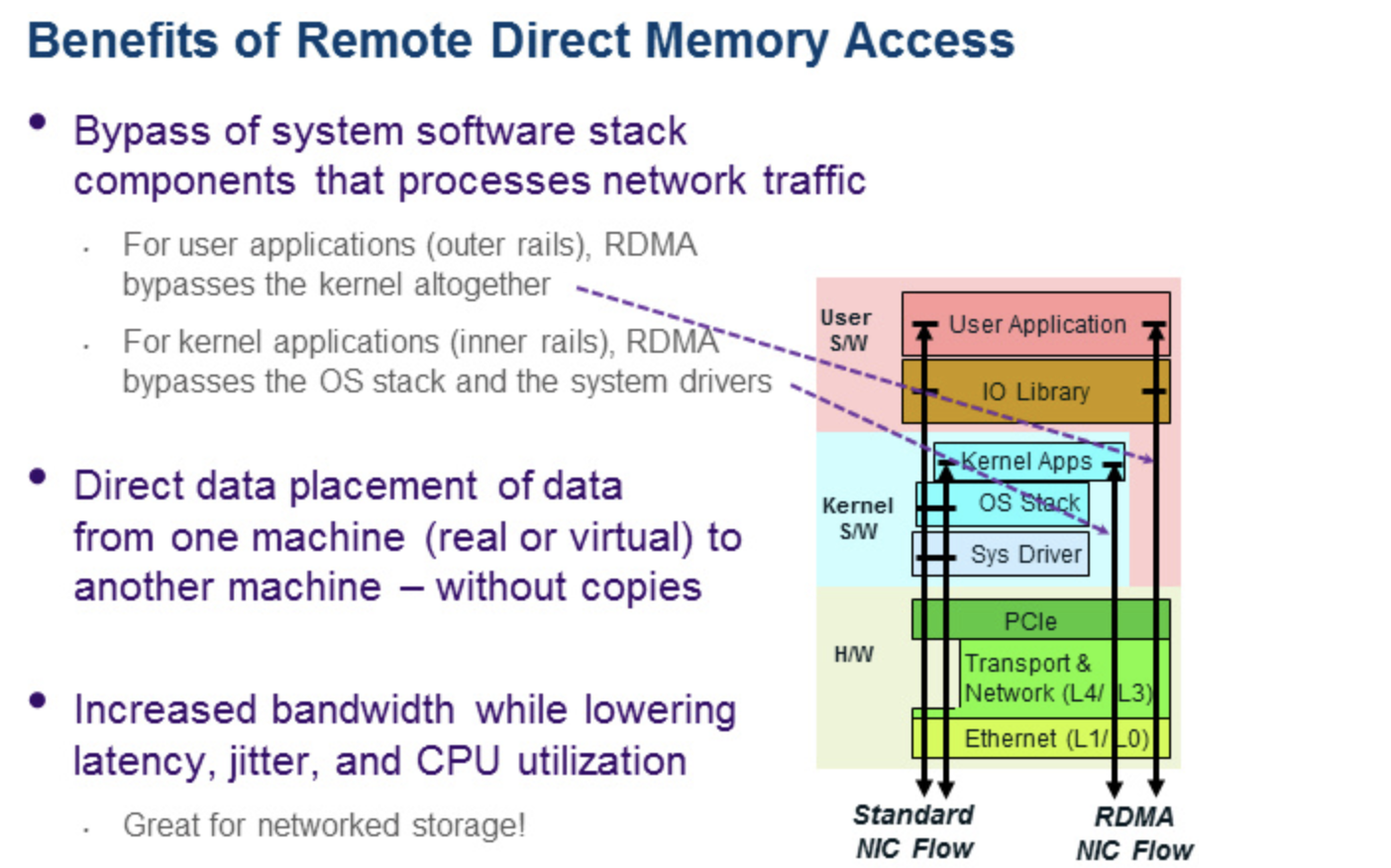
kernel bypass
内核旁路(英语:Kernel Bypass)
系统网络优化可以有两方面的工作可以做:1 绕开内核(bypass);2 用硬件替代软件(offload)。
绕开内核
1.不使用内核子系统的功能,采用自己实现的相同功能的代码来处理
2.从用户空间直接访问和控制设备内存以避免数据从设备拷贝到内核,再从内核拷贝到用户空间
硬件替代:
1.专用的硬件设备替代软件的部分功能
2.典型的用硬件替代软件的例子有:DMA engines, GPUs, Rendering screens,cryptography,TOE(TCP Offload Engines).
Verbs API
IBM RDMA support
RoCE
RDMA over Converged Ethernet (RoCE) is a network protocol that allows remote direct memory access (RDMA) over an Ethernet network.There are two RoCE versions, RoCE v1 and RoCE v2.
RoCE v1 is an Ethernet link layer protocol and hence allows communication between any two hosts in the same Ethernet broadcast domain.
RoCE v2 is an internet layer protocol which means that RoCE v2 packets can be routed.
Although the RoCE protocol benefits from the characteristics of a converged Ethernet network, the protocol can also be used on a traditional or non-converged Ethernet network.
DPDK
DPDK is the Data Plane Development Kit that consists of libraries to accelerate packet processing workloads running on a wide variety of CPU architectures.
NUMA
非统一内存访问架构(英语:Non-uniform memory access,简称NUMA)是一种为多处理器的计算机设计的内存,内存访问时间取决于内存相对于处理器的位置。在NUMA下,处理器访问它自己的本地内存的速度比非本地内存(内存位于另一个处理器,或者是处理器之间共享的内存)快一些。
在NUMA架构出现前,CPU欢快的朝着频率越来越高的方向发展。受到物理极限的挑战,又转为核数越来越多的方向发展。如果每个core的工作性质都是share-nothing(类似于map-reduce的node节点的作业属性),那么也许就不会有NUMA。由于所有CPU Core都是通过共享一个北桥来读取内存,随着核数如何的发展,北桥在响应时间上的性能瓶颈越来越明显。于是,聪明的硬件设计师们,先到了把内存控制器(原本北桥中读取内存的部分)也做个拆分,平分到了每个die上。于是NUMA就出现了!
CPU平均划分为若干个Chip(不多于4个),每个Chip有自己的内存控制器及内存插槽.
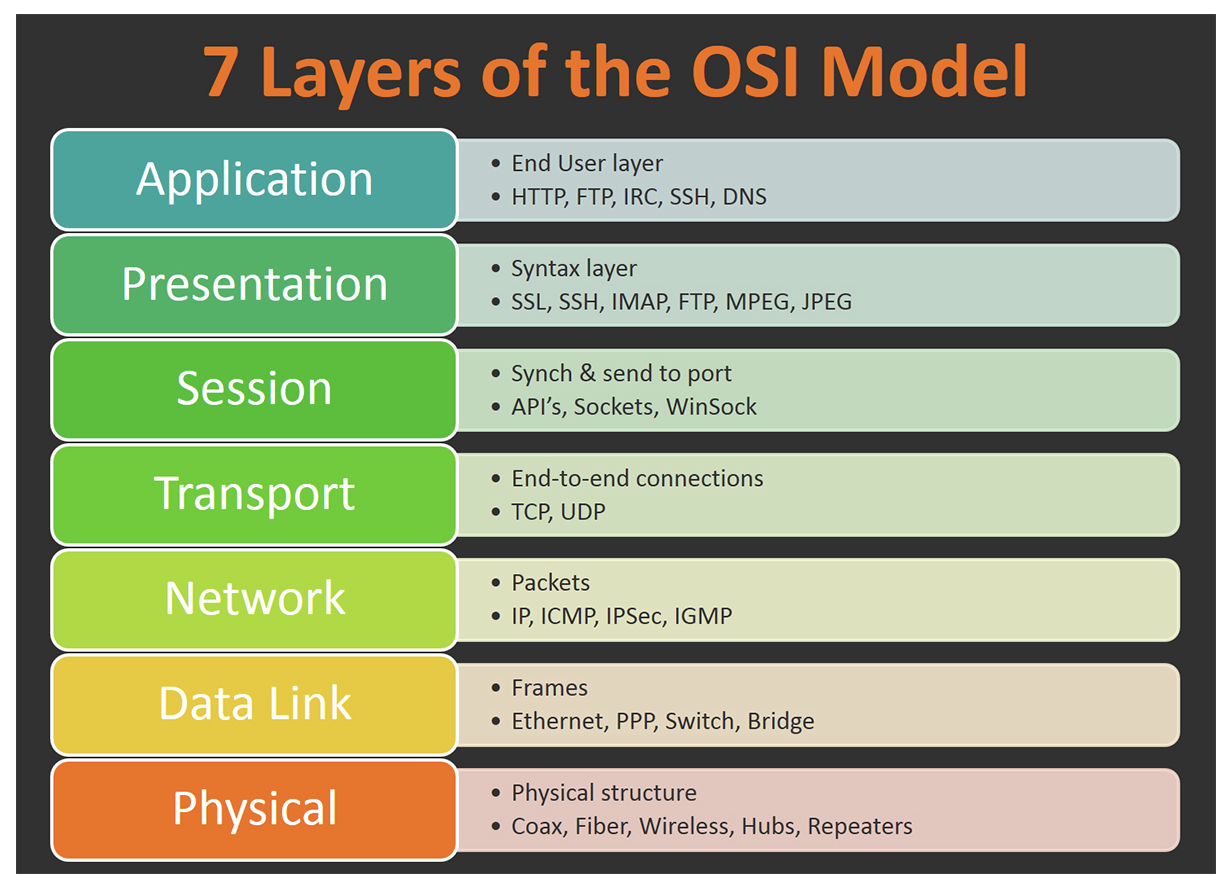
OSI
开放式系统互联通信参考模型,简称为OSI模型,一种概念模型,由国际标准化组织提出,一个试图使各种计算机在世界范围内互连为网络的标准框架。
Infiniband
InfiniBand(直译为“无限带宽”技术,缩写为IB)是一个用于高性能计算的计算机网络通信标准,它具有极高的吞吐量和极低的延迟,用于计算机与计算机之间的数据互连。InfiniBand也用作服务器与存储系统之间的直接或交换互连,以及存储系统之间的互连。是一种网络协议栈,和TCP/IP协议完全不一样
PCIe
Peripheral Component Interconnect Express2004年,Intel再一次带领小伙伴革了PCI的命。PCI express(PCIe,注意官方写法是这样,而不是PCIE或者PCI-E)诞生了,其后又经历了两代,现在是第三代,gen4有望在2017年公布,而gen5已经开始起草中。
PCI Express,简称PCI-E,官方简称PCIe,是電腦匯流排PCI的一種,它沿用現有的PCI編程概念及通訊標準,但建基於更快的串行通信系統。
giga, Kilo, mega, giga, tera, peta, exa, zetta :
全称 简写 kilo K meg M giga G tera T peta P exa E zetta Z yotta Y 在电子及物理领域,是以10为底的幂进行计量,以10^3为增量进位。如1K=10^3, 1M=10^6。如物理的质量、功率、能量、电压、电流。如二进制数据传输速度。
DRAM:
动态随机存取存储器(Dynamic Random Access Memory,DRAM)是一种半导体記憶體,主要的作用原理是利用電容內儲存電荷的多寡來代表一個二进制位元(bit)
BLAS:OpenBLAS
BLAS(Basic Linear Algebra Subprograms,基础线性代数程序集)是一个应用程序接口(API)标准,用以规范发布基础线性代数操作的数值库(如矢量或矩阵乘法)In scientific computing, OpenBLAS is an open source implementation of the BLAS (Basic Linear Algebra Subprograms) API with many hand-crafted optimizations for specific processor types. It is developed at the Lab of Parallel Software and Computational Science, ISCAS.
Chunk:
HTTP 报文
Each chunk contains a header which indicates some parameters (e.g. the type of chunk, comments, size etc.) In the middle there is a variable area containing data which are decoded by the program from the parameters in the header.
Chunks may also be fragments of information which are downloaded or managed by P2P programs.
incast congestion : Incast Congestion Control for TCP
TCP incast congestion happens in high-bandwidth and low-latency networks, when multiple synchronized servers send data to a same receiver in parallel . For many important data center applications such as MapReduce and Search, this many-to-one traffic pattern is common. Hence TCP incast congestion may severely degrade their performances, e.g., by increasing response time.
如果在网路中的包太多,就会发生Incast Congestion的问题(可以理解为,network有很多switch,router啥的,一旦一次性发一堆包,这些包同时到达switch,这些switch就会忙不过来)。应对这个问题就是不要让大量包在同一时间发送出去,在客户端限制每次发出去的包的数量(具体实现就是客户端弄个队列)。每次发送的包的数量称为“Window_size”。这个值太小的话,发送太慢,自然延迟会变高;这个值太大,发送的包太多把network_switch搞崩溃了,就可能发生比如丢包之类的情况,可能被当作cache miss,这样延迟也会变高。所以这个值需要调。
Oversubscription 超额
Oversubscription, in a SAN (storage area network) switching environment, is the practice of connecting multiple devices to the same switch port to optimize switch use.
Each SAN port can support a particular communication speed and a Fibre Channel switch may offer 1 Gb, 2 Gb, or 4 Gb FC ports. However, because ports are rarely run at their maximum speed for a prolonged period, multiple slower devices may fan in to a single port to take advantage of unused capacity. For example, a single storage server may not be able to sustain 4 Gbps to a switch port, so two 2 Gb servers or four 1 Gb servers may all be aggregated to that 4 Gb switch port.
就机顶盒的Switch的bandwidth 支持不到那么多设备的带宽.
fat-tree保证没有Oversubbcription(越上越粗,2的指数上升)实际做不到,所以有多种拓扑结构
需要调整收敛比
Several Devices
Xeon E5-2680 v4 system : CPU of Intel
DDR-2400 DIMMs 第四代双倍数据存储器
GTX 1080 Ti GPU 显卡
Mellanox ConnectX-3 Infiniband card with 56 Gbps
Mellanox SX6025 56 Gbps 36-port switch.
bps网络传输率:
规定使用「比特每秒」(bits或bps)为单位,经常和国际单位制词头关联在一起,如「千」(kbit/s或kbps),「兆」(百萬)(Mbit/s或Mbps),「吉」(Gbit/s或Gbps)和「太」(Tbit/s或Tbps)
CentOS 7.3
CentOS是Linux发行版之一,它是来自于Red Hat Enterprise Linux依照开放源代码规定发布的源代码所编译而成。由于出自同样的源代码,因此有些要求高度稳定性的服务器以CentOS替代商业版的Red Hat Enterprise Linux使用
CUDA 8
CUDA是由NVIDIA所推出的一种集成技术,是该公司对于GPU的正式名称。通过这个技术,用户可利用NVIDIA的GeForce 8以后的GPU和较新的Quadro GPU进行计算。亦是首次可以利用GPU作为C-编译器的开发环境。NVIDIA营销的时候,往往将编译器与架构混合推广,造成混乱
PS-Lite
MXNet之ps-lite及parameter server原理
ps-lite框架是DMLC组自行实现的parameter server通信框架,是DMLC其他项目的核心,例如其深度学习框架MXNET的分布式训练就依赖ps-lite的实现。
DMLC Distributed (Deep) Machine Learning Community
–A Community of Awesome Machine Learning Projects
GCC
GNU编译器套装,指一套编程语言编译器,以GPL及LGPL许可证所发行的自由软件,也是GNU项目的关键部分,也是GNU工具链的主要组成部分之一。GCC也常被认为是跨平台编译器的事实标准。1985年由理查德·马修·斯托曼开始发展,现在由自由软件基金会负责维护工作。 原名为GNU C语言编译器,因为它原本只能处理C语言GNU是一个自由的操作系统,其内容软件完全以GPL方式发布。这个操作系统是GNU计划的主要目标,名称来自GNU’s Not Unix!的递归缩写,因为GNU的设计类似Unix,但它不包含具著作权的Unix代码。GNU的创始人,理查德·马修·斯托曼,将GNU视为“达成社会目的技术方法”。
GNU Not Unix
OpenMPI & MVAPICH
The Open MPI Project is an open source Message Passing Interface implementation that is developed and maintained by a consortium of academic, research, and industry partners.Open MPI is therefore able to combine the expertise, technologies, and resources from all across the High Performance Computing community in order to build the best MPI library available. Open MPI offers advantages for system and software vendors, application developers and computer science researchers.
The MVAPICH project is led by Network-Based Computing Laboratory (NBCL) of The Ohio State University. The MVAPICH2 software, based on MPI 3.1 standard, delivers the best performance, scalability and fault tolerance for high-end computing systems and servers using InfiniBand, Omni-Path, Ethernet/iWARP, and RoCE networking technologies.
SSE
SSE(Streaming SIMD Extensions)在其计算机芯片Pentium III中引入的指令集,是继MMX的扩展指令集。SSE指令集提供了70条新指令。
Open MP
The OpenMP API specification for parallel programmingOpenMP(Open Multi-Processing)是一套支持跨平台共享内存方式的多线程并发的编程API.
OpenMP采用可移植的、可扩展的模型,为程序员提供了一个简单而灵活的开发平台,从标准桌面计算机到超级计算机的并行应用程序接口。
内存优化总结:ptmalloc、tcmalloc和jemalloc
系统的物理内存是有限的,而对内存的需求是变化的,程序的动态性越强,内存管理就越重要,选择合适的内存管理算法会带来明显的性能提升。
目前大部分服务端程序使用glibc提供的malloc/free系列函数,而glibc使用的ptmalloc2在性能上远远弱后于google的tcmalloc和facebook的jemalloc
Several ML CNN Models:
基于Imagenet数据集:
ResNet
AlexNet
VGG
GoogleNet
Inception V3
GHC
Grace Hopper Conference (GHC)是庆祝女性在计算领域取得的成就的全球盛会
Serialization
in the context of data storage, serialization is the process of translating data structures or object state into a format that can be stored (for example, in a file or memory buffer) or transmitted (for example, across a network connection link) and reconstructed later (possibly in a different computer environment)
AMD EPYC
AMD EPYC (霄龙) 服务器处理器
Stream Triad performance
STREAM 是业界广为流行的综合性内存带宽实际性能 测量工具之一。随着处理器处理核心数量的增多,内存带宽对于提升整个系统性能越发重要
通过测试的内容我们可以了解服务器的具体性能及其优缺点,首先我们在SUSE SLES 11到平台下进行了StreamTRIAD测试,该测试分为四组数据,分别是复制、scale、添加以及triad(以上三项的综合)
GLOO:The Function Gateway built on top of Envoy
Gloo is a high-performance, plugin-extendable, platform-agnostic API Gateway built on top of Envoy. Gloo is designed for microservice, monolithic, and serverless applications.
Overhead
overhead is any combination of excess or indirect computation time, memory, bandwidth, or other resources that are required to perform a specific task. It is a special case of engineering overhead.
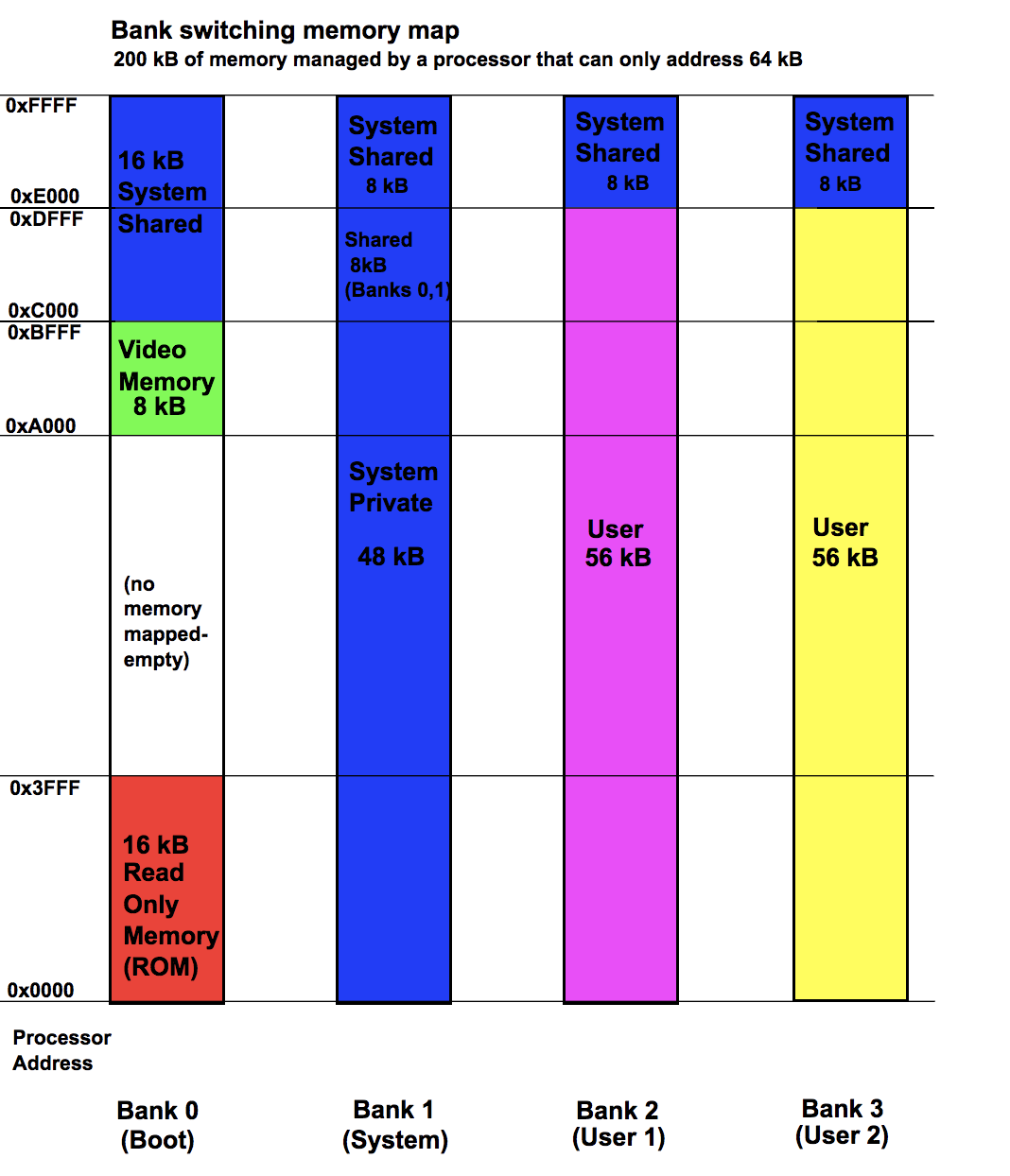
Memory map:
用于处理器的存储体切换存储器的假设存储器映射,其仅能够寻址64kB。 该方案显示200 kB的内存,其中处理器随时只能访问64kb。操作系统必须管理存储体切换操作,以确保当处理器无法访问部分存储器时程序执行可以继续
在计算机科学中,存储器映射是数据结构(通常驻留在存储器本身中),指示存储器的布局方式。 内存映射在操作系统的不同部分可能具有不同的含义
它是使用关联内存的最快,最灵活的缓存组织。 关联存储器存储存储器字的地址和内容。
















Academic iterms used in paper:
序号 英文 中文 1 pinpoint these bottlenecks 精确定位到瓶颈所在 2 interoperability 操作性 3 rendezvous 会合 4 Nonce 一次性秘钥 5 Network stack 网络协议栈 6 Metadata 元数据,描述其他资料资讯的资料 7 element-wise 按元素 8 prototype 原型 9 fine-grained 细优化,细粒度 10 shard 碎片 11 overlap 交叠 12 non-colocated 非同位 13 overhead 负载 14 compute-bound (计算密集)CPU瓶颈 (受计算限制的) 15 workload 工作量 16 colocated 合作 17 arbitrarily 任意 18 caching 高速缓存 19 key-chunking 数据块 20 scalabbility 可扩展性 21 queue-pair connection 队列链接 22 loopback 回环网卡 23 microbenchmark 基准化分析法 24 tradeoff 优劣 25 invocation 调用 26 amortized cost 摊销 27 orthogonal 正交 28 invocation 调用 29 multi-tenant 多细粒度 30 one-shot registration 一次性注册 31 locality-preserving 局部保留 32 incur 招来,招致 33 load balancing 负载均衡 34 hybrid synchronization 混合同步
Cubrid
Cubrid
有很好的网络介绍